
WordPiece 也是一种子词构建算法,我们在中文语料中使用的 BertTokenizer 就是使用这种分词算法,从这一点来看,WordPiece 算法要比 BPE 算法更加适合中文语料的分词场景。
class BertTokenizer(PreTrainedTokenizer):
Construct a BERT tokenizer. Based on WordPiece.
BPE 和 WordPiece 都是子词构建算法,他们两个最大的区别是做子词合并时,BPE 是寻找合并之后频数最高的两个子词进行合并,而 WordPiece 计算步骤如下:

https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/37842.pdf
分词的目标就是最大化训练数据的似然函数:
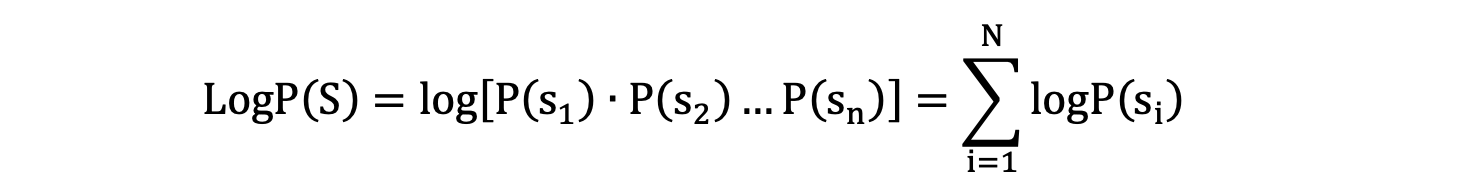
下图公式中,A 和 B 为待合并的两个子词:
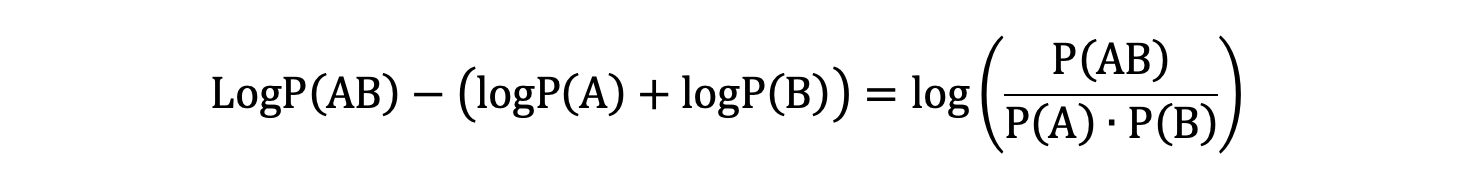
示例代码:
import tokenizers.pre_tokenizers
from tokenizers import Tokenizer
from tokenizers.models import WordPiece
from tokenizers.trainers import WordPieceTrainer
from tokenizers.pre_tokenizers import WhitespaceSplit
def test():
document = ['我爱吃烤鸭'] * 5 + ['我也爱喝啤酒']
print(document)
# 指定分词器使用 BPE 算法模型,并设置特殊 UNK 标记
tokenizer = Tokenizer(model=WordPiece())
# 设置单词的分割方式
tokenizer.pre_tokenizer = WhitespaceSplit()
# 构建训练器
trainer = WordPieceTrainer(vocab_size=20)
# 开始训练
tokenizer.train_from_iterator(document, trainer)
# 保存分词器
tokenizer.save('./tokenizer.json')
if __name__ == '__main__':
test()
分词结果:
"vocab": {
"也": 0,
"吃": 1,
"啤": 2,
"喝": 3,
"我": 4,
"烤": 5,
"爱": 6,
"酒": 7,
"鸭": 8,
"##也": 9,
"##爱": 10,
"##喝": 11,
"##啤": 12,
"##酒": 13,
"##吃": 14,
"##烤": 15,
"##鸭": 16,
"我爱": 17,
"##吃烤": 18,
"我爱吃烤": 19
}
 冀公网安备13050302001966号
冀公网安备13050302001966号