
SBert 模型基于孪生网络来训练 sentence 向量,这篇文章参考了其实现,在 tiny albert 中文预训练模型基础上进行微调,使之能够生成 sentence 向量。SBert 是一个有监督的 sentence embedding 训练模型。
import pandas as pd
import torch.nn as nn
import torch
from transformers import AlbertModel
from transformers import BertTokenizer
from torch.utils.data import DataLoader
import random
import torch.optim as optim
from tqdm import tqdm
import time
from sentence_transformers import util
import numpy as np
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
1. 模型构建
模型架构如下图所示:
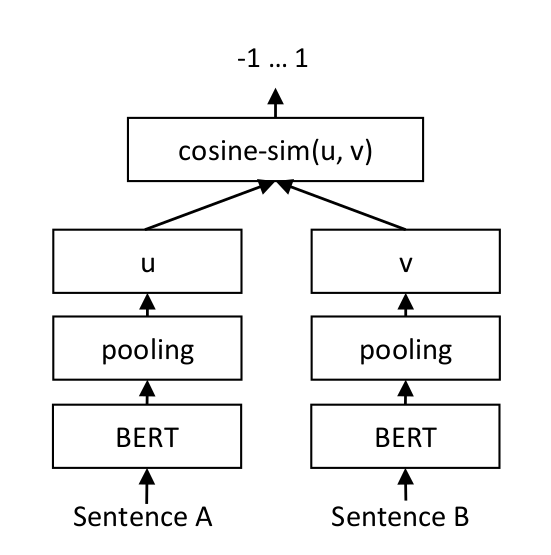
我们将句子 A 和 B 分别送入到 albert 模型中,得到 A 和 B token 向量,然后在 pooling 阶段使用平均 token 向量作为句向量,计算余弦相似度,最后使用 MSE 来计算相似度和标签的均方误差损失。
在实现的时候,注意不要直接把 A 和 B 拼成一个 pair 送入到 albert 模型,这是因为对于一个 pair,albert 的自注意力机制会使得 A 中的 token 注意到 B 中的 token。所以,如果输入一个 pair 时,我们需要分别、独立计算 A 和 B 的向量表示。
例如:一个批次的 pair 为 [(‘我爱你’, ‘我非常恨你’), (‘他是谁’, ‘我认识他吗’)],我们先将输入格式改成 [(我爱你, 他是谁), (我非常恨你, 我认识他吗)], 然后第一个批次的两个句子送入到 albert 计算向量表示,再将第二个批次的句子送入到模型计算向量表示,也就是说,一个批次的数据会送入模型 2 次计算。最后,相应位置的句向量计算余弦相似度。
模型存储时,只需要存储模型和分词器即可。
注意:我们这里使用平均 token 向量作为句向量,当然也可以使用 [cls],或者相应位置最大值组成的向量来表示句向量等等…
实现代码:
class SentenceBert(nn.Module):
def __init__(self, model_path='model/albert_chinese_tiny'):
super(SentenceBert, self).__init__()
self.basemodel = AlbertModel.from_pretrained(model_path)
self.tokenizer = BertTokenizer.from_pretrained(model_path)
# 输入: [(sentence1, sentence2), (sentence1, sentence2)...]
def forward(self, batch_sentence_pairs):
# 1. 将 sentence1 放到第一个列表中,sentence2 放到第二个列表中
batch_sentence = [[], []]
for sentence1, sentence2 in batch_sentence_pairs:
batch_sentence[0].append(sentence1)
batch_sentence[1].append(sentence2)
def batch_encode_plus(sentences):
batch_inputs = self.tokenizer.batch_encode_plus(sentences,
padding='longest',
return_tensors='pt')
# 将张量移动到 device 计算设备
batch_inputs = { key: value.to(device) for key, value in batch_inputs.items()}
return batch_inputs
# 2. 分别计算第一个、第二个列表中所有句子的编码
self.basemodel.train()
batch_encodes = [batch_encode_plus(sentence) for sentence in batch_sentence]
batch_outputs = [self.basemodel(**sentence_encode) for sentence_encode in batch_encodes]
# 3. 计算每个句子的向量表示,这里使用平均 token 向量的方式表示 sentence 向量
sentence_embeddings = []
for index, outputs in enumerate(batch_outputs):
token_embd = outputs.last_hidden_state
token_mask = batch_encodes[index]['attention_mask'].unsqueeze(-1).expand(token_embd.size())
sentence_embedding = torch.sum(token_embd * token_mask, 1) / torch.sum(token_mask, 1)
sentence_embeddings.append(sentence_embedding)
# 4. 计算 sentence1 和 sentence2 的相似度
similarities = torch.cosine_similarity(sentence_embeddings[0], sentence_embeddings[1])
similarities = nn.Identity()(similarities)
return similarities
def save(self, model_path_name):
self.basemodel.save_pretrained(model_path_name)
self.tokenizer.save_pretrained(model_path_name)
def encode(self, sentence):
self.basemodel.eval()
sentence_encode = self.tokenizer.encode_plus(sentence, return_tensors='pt')
with torch.no_grad():
sentence_output = self.basemodel(**sentence_encode)
token_embd = sentence_output.last_hidden_state
embedding = torch.sum(token_embd, dim=1) / token_embd.shape[1]
return embedding.squeeze()
2. 模型训练
由于基于前面的网络模型架构图,我们最终需要计算 MSE 损失。原始的问题数据,并不存正负样本,所以我们自己构造了一些正样本,正样本是通过对原始数据进行同义词替换、回译等方式构建,负样本则是随机选择其他不相关样本。
def collate_function(batch_inputs):
sentence_pairs = []
labels = []
for sentence1, sentence2, label in batch_inputs:
id = random.randint(0, 1)
if id == 1:
s1 = sentence1
s2 = sentence2
else:
s1 = sentence2
s2 = sentence1
sentence_pairs.append((s1, s2))
labels.append(label)
return sentence_pairs, torch.tensor(labels, device=device).float()
from torch.optim.lr_scheduler import ReduceLROnPlateau
def train():
estimator = SentenceBert()
estimator.to(device)
traindata = pd.read_csv('data/sentence/train.csv', index_col=0).to_numpy().tolist()
dataloader = DataLoader(traindata, batch_size=128, shuffle=True, collate_fn=collate_function)
criterion = nn.MSELoss()
optimizer = optim.Adam(params=estimator.parameters(), lr=1e-4)
scheduler = ReduceLROnPlateau(optimizer, factor=0.7, patience=2, cooldown=2)
for epoch in range(40):
total_loss = 0.0
total_size = 0.0
proress = tqdm(range(len(dataloader)))
for sentence_pairs, labels in dataloader:
outputs = estimator(sentence_pairs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
total_size += len(labels)
proress.set_description('loss %.5f lr %.8f' % (total_loss, scheduler.optimizer.param_groups[0]['lr']))
proress.update()
proress.close()
optimizer.step()
scheduler.step(total_loss)
# 存储模型
estimator.save('model/embed_model_%d' % epoch)
def test():
estimator = SentenceBert('model/embed_model_36')
data = pd.read_csv('data/processed_data/question.csv', index_col=0)
questions = data['question']
question_embeddings = []
progress = tqdm(range(len(questions)))
for question in questions:
embedding = estimator.encode(question)
question_embeddings.append(embedding.tolist())
progress.update()
progress.close()
input_question = '我被非法拘禁了'
start = time.time()
input_embedding = estimator.encode(input_question)
print('问题编码时间:', time.time() - start)
similarities = []
for embedding in question_embeddings:
sim = util.cos_sim(embedding, input_embedding)
similarities.append(sim.item())
selected_question = np.argsort(-np.array(similarities))[:5]
print(np.array(similarities)[selected_question])
print(questions[selected_question])
if __name__ == '__main__':
test()
 冀公网安备13050302001966号
冀公网安备13050302001966号