
BiEncoder 将句子 A 和 句子 B 分别输入 Bert 模型,得到两个句子向量,然后使用余弦相似度比较两个输入句子。而 CrossEncoder 则将句子 A 和 B 拼接成一个句子,送入到 Bert 模型,得到 0-1 之间的分数作为两个句子的相似性。
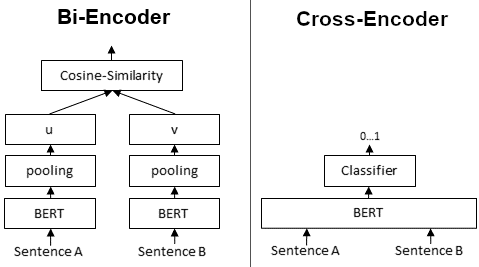
两者最大区别是:BiEncoder 会对输入的句子分别产生句向量,而 CrossEncoder 则不会为输入的两个句子分别产生句向量。从性能上来比较的话,CrossEncoder 要比 BiEncoder 要更好。
CrossEncoder 性能高于 BiEncoder,但是在大数据集中扩展效果不佳。例如,将 10000 个句子与交叉编码器分组需要计算 4950 万个句子组合的相似性分数,这大约需要65小时。使用 BiEncoder 算每个句子的嵌入只需5秒。
将 CrossEncoder 和 BiEncoder 组合起来是有意义的,例如在信息检索/语义搜索场景中:首先,您使用高效的 BiEncoder 来检索查询的前 100 个最相似的句子。然后使用 CrossEncoder 计算每个组合的分数来重新排名 100 个候选。
预训练模型:https://www.sbert.net/docs/pretrained-models/ce-msmarco.html
from sentence_transformers import CrossEncoder
def test():
model = CrossEncoder('amberoad/bert-multilingual-passage-reranking-msmarco',
max_length=256,
num_labels=2)
scores = model.predict([('我是个生活在北京的中国平民', '前天老王去他邻居家玩了'),
('我是个生活在北京的中国平民', '我是生活在北京的中国人')])
# 0 标签表示不相关, 1 标签表示相关
print(scores)
if __name__ == '__main__':
test()
程序输出结果:
[[ 4.7365217 -3.8824842] [-3.8670764 3.4375916]]
 冀公网安备13050302001966号
冀公网安备13050302001966号