


本文将从零开始,详细讲解如何使用递归神经网络(RNN/GRU/LSTM)实现文本情感分类。我们将基于 PyTorch 从头构建一个模型,并应用于情感分析任务。内容涵盖数据预处理、构建词汇表、分词器、模型搭建与训练,最终完成情感分类性能的评估。
conda create -n sentiment-env python=3.10 pip install jieba -i https://pypi.tuna.tsinghua.edu.cn/simple/ pip install torch --index-url https://download.pytorch.org/whl/cu126 pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple/ pip install tqdm -i https://pypi.tuna.tsinghua.edu.cn/simple/ pip install scikit-learn -i https://pypi.tuna.tsinghua.edu.cn/simple/ pip install matplotlib==3.7.1 -i https://pypi.tuna.tsinghua.edu.cn/simple/ pip install numpy==1.26.4 -i https://pypi.tuna.tsinghua.edu.cn/simple/
1. 准备数据
该代码用于微博情感分析数据的预处理。主要流程包括:
- 数据存储:使用
pickle保存语料库、训练集和测试集,以便后续使用。 - 加载数据:读取
weibo_senti_100k.csv,去除缺失值。 - 数据分析:统计类别分布。
- 数据集划分:按 85:15 比例分割训练集和测试集,确保类别平衡。
创建 01-准备数据.py 文件并添加如下代码:
import jieba
import logging
jieba.setLogLevel(logging.CRITICAL)
import pickle
import pandas as pd
from collections import Counter
from sklearn.model_selection import train_test_split
def demo():
# 加载数据
data = pd.read_csv('weibo_senti_100k/weibo_senti_100k.csv')
data = data.dropna()
inputs = data['review'].to_numpy().tolist()
labels = data['label'].to_numpy().tolist()
print('类别分布:', Counter(labels))
# 数据集分割
train_data, test_data = train_test_split(data, test_size=0.15, stratify=labels, random_state=42)
corpus = data['review'].to_numpy().tolist()
train_data = train_data.to_numpy().tolist()
test_data = test_data.to_numpy().tolist()
print(train_data[:3])
# 存储数据
pickle.dump(inputs, open('data/corpus.pkl', 'wb'))
pickle.dump(train_data, open('data/train.pkl', 'wb'))
pickle.dump(test_data, open('data/test.pkl', 'wb'))
if __name__ == '__main__':
demo()
类别分布: Counter({0: 59995, 1: 59993})
[[0, '草泥马又受伤了~最近时运不济啊!干啥啥不爽!!!不过这次泥煤的伤口怎么那么欢乐!谁能告诉我膝盖着地为毛高处伤口比低处伤口小那么多[泪]此图可能引起生理上的不适,围观者慎重~'], [0, '求高人解梦;梦的情况见下图。快艇是丛琅勃拉邦到清孔,飞机是从琅勃拉邦到清迈的老挝航空班机。[抓狂] 求解! #美图秀秀iPhone版#'], [1, 'Niubility![哈哈]']]
2. 构建词典
该代码用于构建文本词汇表。主要流程包括:
- 加载数据:读取
corpus.pkl语料库和stopwords.txt停用词。 - 统计词频:对文本进行分词并统计词频。
- 构建词表:过滤低频词和停用词,生成
word_to_id和id_to_word映射。 - 数据存储:使用
pickle保存词汇表,供后续使用。
创建 02-构建词表.py 文件并添加如下代码:
import jieba
import logging
jieba.setLogLevel(logging.CRITICAL)
import pickle
from collections import Counter
def demo():
corpus = pickle.load(open('data/corpus.pkl', 'rb'))
stopwords = {word.strip() for word in open('stopwords.txt')}
word_freq = Counter()
for review in corpus:
words = jieba.lcut(review)
if len(words) == 0:
continue
word_freq.update(words)
# 设定阈值,过滤低频词
word_to_id = {'[PAD]': 0, '[UNK]': 1}
id_to_word = {0: '[PAD]', 1: '[UNK]'}
threshold = 1
start_id = len(word_to_id)
for word, freq in word_freq.items():
if freq >= threshold and word not in stopwords:
word_to_id[word] = start_id
id_to_word[start_id] = word
start_id += 1
print(id_to_word, len(id_to_word))
pickle.dump(word_to_id, open('vocab/word_to_id.pkl', 'wb'))
pickle.dump(id_to_word, open('vocab/id_to_word.pkl', 'wb'))
if __name__ == '__main__':
demo()
3. 分词器
该代码实现了一个基于 jieba 分词的文本 分词器。主要功能包括:
- 加载词汇表:读取
word_to_id.pkl和id_to_word.pkl。 - 编码文本:将文本转换为 ID 序列,并进行
PAD填充。 - 获取词汇表大小、保存/加载分词器。
- 测试示例:对文本进行编码并打印结果。
创建 tokenizer.py 并添加如下代码:
import jieba
import logging
jieba.setLogLevel(logging.CRITICAL)
import pickle
import torch
from torch.nn.utils.rnn import pad_sequence
class Tokenzier:
def __init__(self):
self.word_to_id = pickle.load(open('vocab/word_to_id.pkl', 'rb'))
self.id_to_word = pickle.load(open('vocab/id_to_word.pkl', 'rb'))
self.unk = self.word_to_id['[UNK]']
self.pad = self.word_to_id['[PAD]']
def get_vocab_size(self):
return len(self.word_to_id)
def encode(self, texts):
words = [jieba.lcut(text) for text in texts]
batch_ids, batch_len = [], []
for text in texts:
ids = []
words = jieba.lcut(text)
for word in words:
if word in self.word_to_id:
id = self.word_to_id[word]
else:
id = self.unk
ids.append(id)
batch_ids.append(torch.tensor(ids))
batch_len.append(len(ids))
# 将批次数据 PAD 对齐
batch_ids = pad_sequence(batch_ids, batch_first=True, padding_value=self.pad)
batch_len = torch.tensor(batch_len)
return batch_ids, batch_len
def save(self, path):
pickle.dump(self, open(path, 'wb'))
@classmethod
def load(cls, path):
tokenizer = pickle.load(open(path, 'rb'))
return tokenizer
def demo():
tokenizer = Tokenzier()
batch_ids, batch_len = tokenizer.encode(['梦想有多大,舞台就有多大![鼓掌]', '[花心][鼓掌]//@小懒猫Melody2011: [春暖花开]'])
print(batch_ids)
if __name__ == '__main__':
demo()
4. 模型搭建
该代码实现了一个基于 RNN 的情感分析模型。主要功能包括:
- 定义模型:包含
Embedding、RNN、Linear层,用于文本分类。 - 处理输入:使用
pack_padded_sequence处理变长序列,避免PAD影响计算。 - 模型存储与加载:支持
pickle序列化保存和恢复。 - 测试示例:对文本进行编码、排序并输入模型,输出分类结果。
注意:下面代码中 nn.RNN 可以直接替换为 nn.GRU、nn.LSTM,更容易训练。
创建 estimator.py 文件并添加如下代码:
import torch.nn as nn
import torch
from torch.nn.utils.rnn import pack_padded_sequence
from torch.nn.utils.rnn import pad_packed_sequence
from tokenizer import Tokenzier
import pickle
class SentimentAnalysis(nn.Module):
def __init__(self, vocab_size=0, num_labels=2, padding_idx=0):
super(SentimentAnalysis, self).__init__()
self.vocab_size = vocab_size
self.num_labels = num_labels
self.padding_idx = padding_idx
self.ebd = nn.Embedding(num_embeddings=vocab_size, embedding_dim=128, padding_idx=padding_idx)
self.rnn = nn.RNN(input_size=128, hidden_size=256, batch_first=True)
self.out = nn.Linear(in_features=256, out_features=num_labels)
def __call__(self, input_ids, batch_length):
inputs = self.ebd(input_ids)
# 将带有 pad 的批次输入转换为 PackedSequence 格式,避免 pad 参与 rnn 计算
inputs = pack_padded_sequence(inputs, lengths=batch_length, batch_first=True, enforce_sorted=True)
output, hn = self.rnn(inputs)
# 将 PackedSequence 转换为带有 pad 的批次数据
# output, lens = pad_packed_sequence(output, batch_first=True, padding_value=self.ebd.padding_idx)
# logging.info(f'output: {output.shape}, lens: {lens}, hn: {hn.shape}')
inputs = self.out(hn.squeeze())
return inputs
def save(self, path):
init_param = {'vocab_size': self.vocab_size, 'num_labels': self.num_labels, 'padding_idx': self.padding_idx}
parameters = self.state_dict()
save_data = {'init_param': init_param, 'parameters': parameters}
pickle.dump(save_data, open(path, 'wb'))
@classmethod
def load(cls, path):
params = pickle.load(open(path, 'rb'))
estimator = SentimentAnalysis(**(params['init_param']))
estimator.load_state_dict(params['parameters'])
return estimator
def demo():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
tokenizer = Tokenzier()
batch_inputs, batch_length = tokenizer.encode(['梦想有多大,舞台就有多大![鼓掌]', '[花心][鼓掌]//@小懒猫Melody2011: [春暖花开]'])
estimator = SentimentAnalysis(vocab_size=tokenizer.get_vocab_size(), num_labels=2, padding_idx=tokenizer.pad).to(device)
# 对批次输入根据长度降序排列(注意: 标签也需要相应排序)
sorted_index = torch.argsort(batch_length, descending=True)
batch_inputs = batch_inputs[sorted_index].to(device)
batch_length = batch_length[sorted_index]
outputs = estimator(batch_inputs, batch_length)
print(outputs)
if __name__ == '__main__':
demo()
5. 模型训练
该代码实现了RNN 训练情感分析模型,主要功能包括:
- 数据预处理:加载数据集,使用
Tokenzier编码,并按长度排序。 - 模型训练:使用
CrossEntropyLoss计算损失,AdamW进行优化,并动态调整学习率。 - 训练流程:循环训练 20 轮,更新参数,记录损失,并保存模型和
tokenizer。 - 结果可视化:绘制损失曲线,观察训练效果。
创建 03-模型训练.py 文件并添加如下代码:
import jieba
import logging
jieba.setLogLevel(logging.CRITICAL)
logging.basicConfig(level=logging.INFO, format="%(levelname)s - %(message)s")
import warnings
warnings.filterwarnings('ignore')
import torch
import torch.nn as nn
import pickle
import torch.optim as optim
from torch.optim.lr_scheduler import StepLR
from torch.utils.data import DataLoader
from tqdm import tqdm
import matplotlib.pyplot as plt
import os
import shutil
from estimator import SentimentAnalysis
from tokenizer import Tokenzier
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# watch -n 10 nvidia-smi
def train():
tokenizer = Tokenzier()
estimator = SentimentAnalysis(vocab_size=tokenizer.get_vocab_size(), num_labels=2, padding_idx=tokenizer.pad).to(device)
criterion = nn.CrossEntropyLoss(reduction='mean')
optimizer = optim.AdamW(estimator.parameters(), lr=1e-4)
scheduler = StepLR(optimizer, step_size=1, gamma=0.85)
train_data = pickle.load(open('data/train.pkl', 'rb'))
def collate_fn(batch_data):
batch_inputs, batch_labels = [], []
for label, data in batch_data:
batch_inputs.append(data)
batch_labels.append(label)
batch_inputs, batch_length = tokenizer.encode(batch_inputs)
# 根据长度由大到小排序
sorted_index = torch.argsort(batch_length, descending=True)
batch_labels = torch.tensor(batch_labels)[sorted_index].to(device)
batch_inputs = batch_inputs[sorted_index].to(device)
batch_length = batch_length[sorted_index]
return batch_inputs, batch_length, batch_labels
total_loss, total_epoch = [], 20
for epoch in range(total_epoch):
epoch_loss, epoch_size = 0, 0
dataloader = DataLoader(dataset=train_data, shuffle=True, batch_size=128, collate_fn=collate_fn)
progress = tqdm(range(len(dataloader)), ncols=100, desc='epoch: %2d loss: %07.2f lr: %.7f' % (0, 0, 0))
for batch_inputs, batch_length, batch_labels in dataloader:
# 推理计算
y_preds = estimator(batch_inputs, batch_length)
# 损失计算
loss = criterion(y_preds, batch_labels)
# 梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 参数更新
optimizer.step()
# 当前损失
epoch_loss += loss.item() * len(batch_labels)
epoch_size += len(batch_labels)
# 更新进度
progress.update()
progress.set_description('epoch: %2d loss: %07.2f lr: %.7f' %
(epoch + 1, epoch_loss, scheduler.get_last_lr()[0]))
progress.close()
# 记录轮次损失
total_loss.append(epoch_loss)
# 更新学习率
scheduler.step()
# 模型存储
save_path = f'model/{epoch + 1}/'
if os.path.exists(save_path) and os.path.isdir(save_path):
shutil.rmtree(save_path)
os.mkdir(save_path)
estimator.save(save_path + 'estimator.bin')
tokenizer.save(save_path + 'tokenizer.bin')
# 绘制损失变化
plt.plot(range(total_epoch), total_loss)
plt.grid()
plt.show()
if __name__ == '__main__':
train()
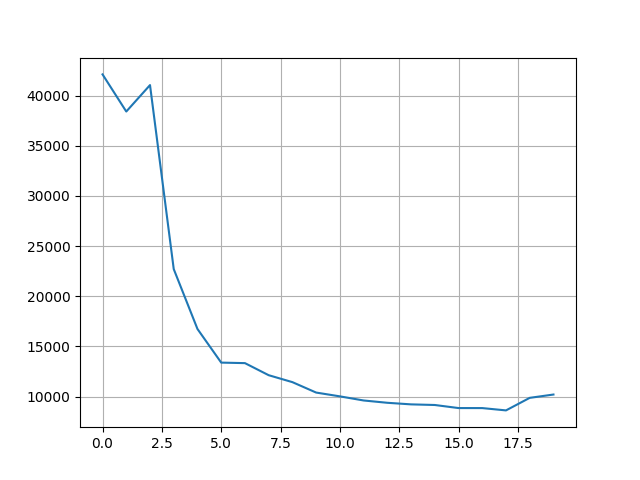
图片展示 20 个 epoch 的在训练集上的总损失变化曲线。随着训练的进行,整体损失呈现下降趋势。
6. 模型评估
该代码实现了情感分析模型评估,主要功能包括:
- 模型加载:根据
model_id加载对应的tokenizer和训练好的模型。 - 数据处理:从测试集加载数据,进行编码并按长度排序。
- 预测与评估:通过模型进行预测,计算预测结果与真实标签的准确率。
- 结果展示:评估多个模型(共21个)并绘制准确率变化曲线。
创建 04-模型评估.py 文件并添加如下代码:
import warnings
warnings.filterwarnings('ignore')
import jieba
import logging
jieba.setLogLevel(logging.CRITICAL)
logging.basicConfig(level=logging.INFO, format="%(levelname)s - %(message)s")
import torch
import pickle
from torch.utils.data import DataLoader
from estimator import SentimentAnalysis
from tokenizer import Tokenzier
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def eval(model_id=5):
if model_id > 0:
tokenizer = Tokenzier.load(f'model/{model_id}/tokenizer.bin')
estimator = SentimentAnalysis.load(f'model/{model_id}/estimator.bin').to(device)
else:
tokenizer = Tokenzier()
estimator = SentimentAnalysis(tokenizer.get_vocab_size(), 2, tokenizer.pad).to(device)
train_data = pickle.load(open('data/test.pkl', 'rb'))
def collate_fn(batch_data):
batch_inputs, batch_labels = [], []
for label, data in batch_data:
batch_inputs.append(data)
batch_labels.append(label)
batch_inputs, batch_length = tokenizer.encode(batch_inputs)
# 根据长度由大到小排序
sorted_index = torch.argsort(batch_length, descending=True)
batch_labels = torch.tensor(batch_labels)[sorted_index].to(device)
batch_inputs = batch_inputs[sorted_index].to(device)
batch_length = batch_length[sorted_index]
return batch_inputs, batch_length, batch_labels
dataloader = DataLoader(dataset=train_data, shuffle=True, batch_size=128, collate_fn=collate_fn)
y_pred, y_true = [], []
for batch_inputs, batch_length, batch_labels in dataloader:
with torch.no_grad():
logits = estimator(batch_inputs, batch_length)
model_labels = torch.argmax(logits, dim=-1)
y_pred.extend(model_labels.tolist())
y_true.extend(batch_labels.tolist())
accuracy = accuracy_score(y_true, y_pred)
print('model: %2d, accuracy: %.3f' % (model_id, accuracy))
return accuracy
def demo():
scores = []
for model_id in range(21):
score = eval(model_id)
scores.append(score)
plt.plot(range(21), scores)
plt.grid()
plt.show()
if __name__ == '__main__':
demo()
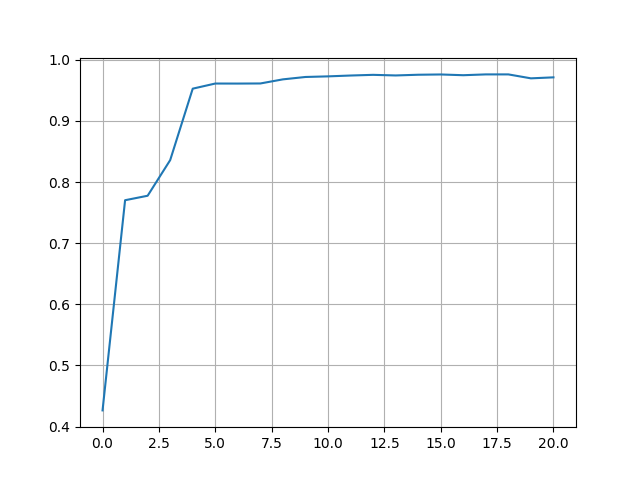
图片展示了模型在训练前、每一个 epoch 训练结束时,模型在测试集上的准确率变化曲线。
 冀公网安备13050302001966号
冀公网安备13050302001966号