
AdaBoost (Adaptive Boosting, 自适应提升)是 Boosting 算法的一种实现,是一种用于分类问题的算法,它用弱分类器的线性组合来构造强分类器。弱分类器的性能比随机猜测强就行,即可构造出一个非常准确的强分类器。其特点是:训练时,样本具有权重,并且在训练过程中动态调整。被分错的样本的样本会加大权重,算法更加关注难分的样本。
其训练过程,主要关注三个计算:
- 计算样本的权重
- 如果样本被分类正确,则降低其权重,表示后续训练关注力度可降低
- 如果样本被分类错误,则提高其权重,表示后续训练需要重点关注的样本
- 样本权重在训练的过程中自动调整
- 计算基学习器的错误率
- 错误分类的样本越多,样本权重越大,则其错误率越高
- 错误分类的样本越少,样本的权重小,则其错误率越低
- 计算弱学习器的权重
- 弱学习器错误率低,则其权重较大,对预测的结果的影响较大
- 弱学习器错误率高,则其权重较低,对预测的结果的影响较小
- 弱学习器错误率高于 0.5,则弱学习器权重为负权重
模型错误率对样本权重更新的影响:
- 如果模型的错误率大于 0.5,则模型的权重就是负数.
- 如果模型的权重是负数(错误率大于0.5):
- 当该模型把样本分类正确时,样本权重会上升
- 当该模型把样本分类错误时,样本权重反而会下降
- 如果模型的权重是正数(错误率小于0.5):
- 当该模型把样本分类正确时,样本权重下降
- 当该模型把样本分类错误时,样本权重上升
1. AdaBoost 构建
- 初始化训练数据权重相等,训练第 1 个学习器
- 如果有 100 个样本,则每个样本的初始化权重为:1/100
- 根据预测结果计算、更新:样本权重、模型权重
- 根据新权重的样本集训练第 2 个学习器
- 根据预测结果计算、更新:样本权重、模型权重
- 迭代训练在前一个学习器的基础上,根据新的样本权重训练当前学习器
- 直到训练出 m 个数的弱学习器
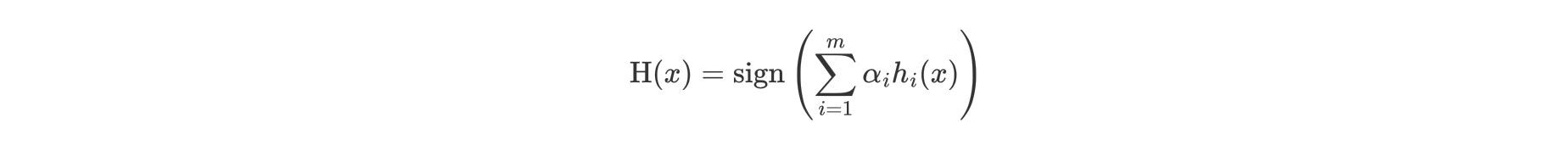
公式中:
- α 为模型的权重
- m 为弱学习器数量
- hi(x) 表示弱学习器
- H(x) 输出结果大于 0 则归为正类,小于 0 则归为负类。

2. 构建第一个基学习器(决策树)
分析案例:
下面为训练数数据,假设弱分类器由 x 产生,其阈值 v 使该分类器在训练数据集上的分类误差率最低,试用 Adaboost 算法学习一个强分类器。

假设:我们使用决策树作为基学习器。
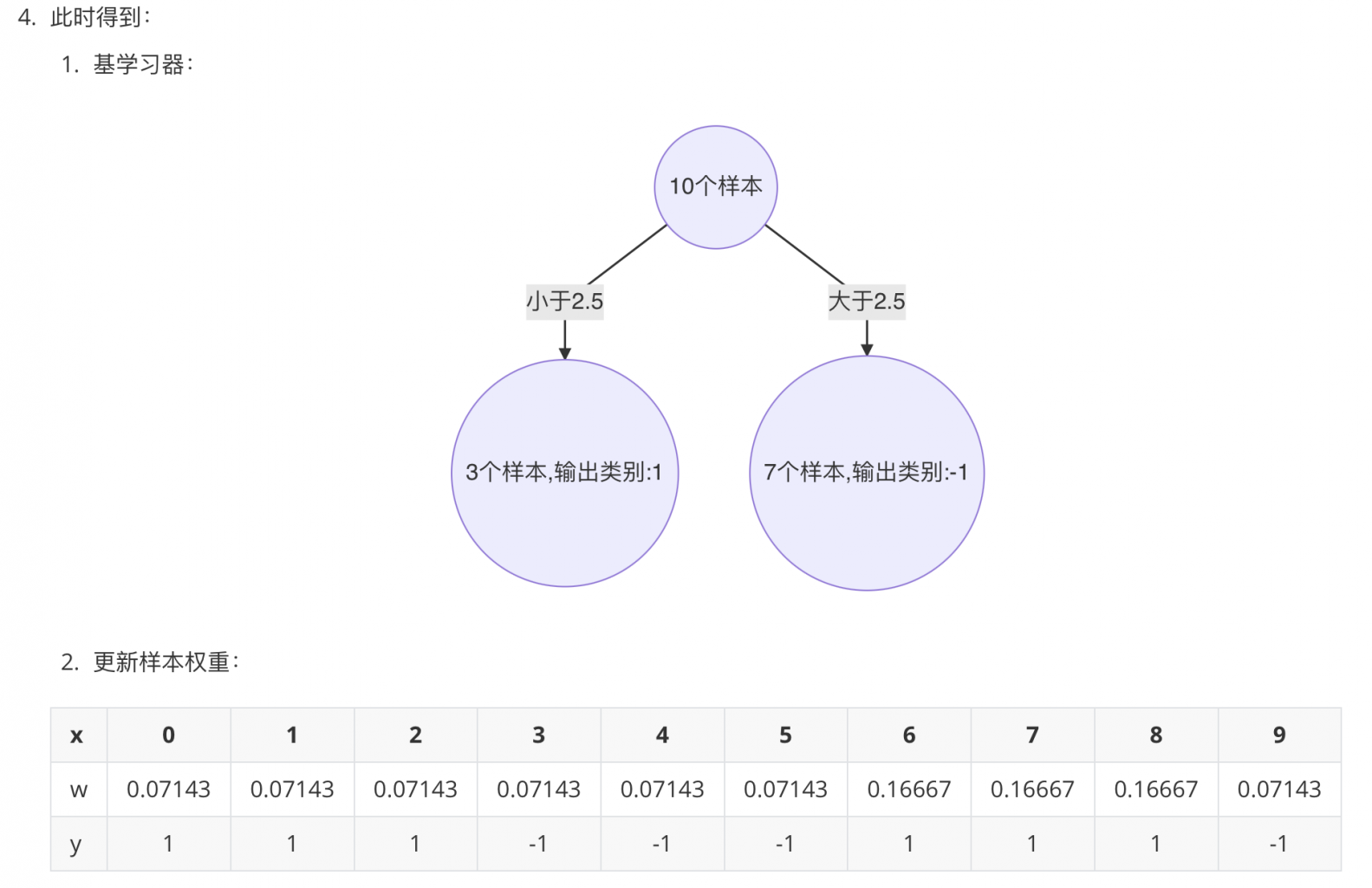
3. 构建第二个基学习器(决策树)

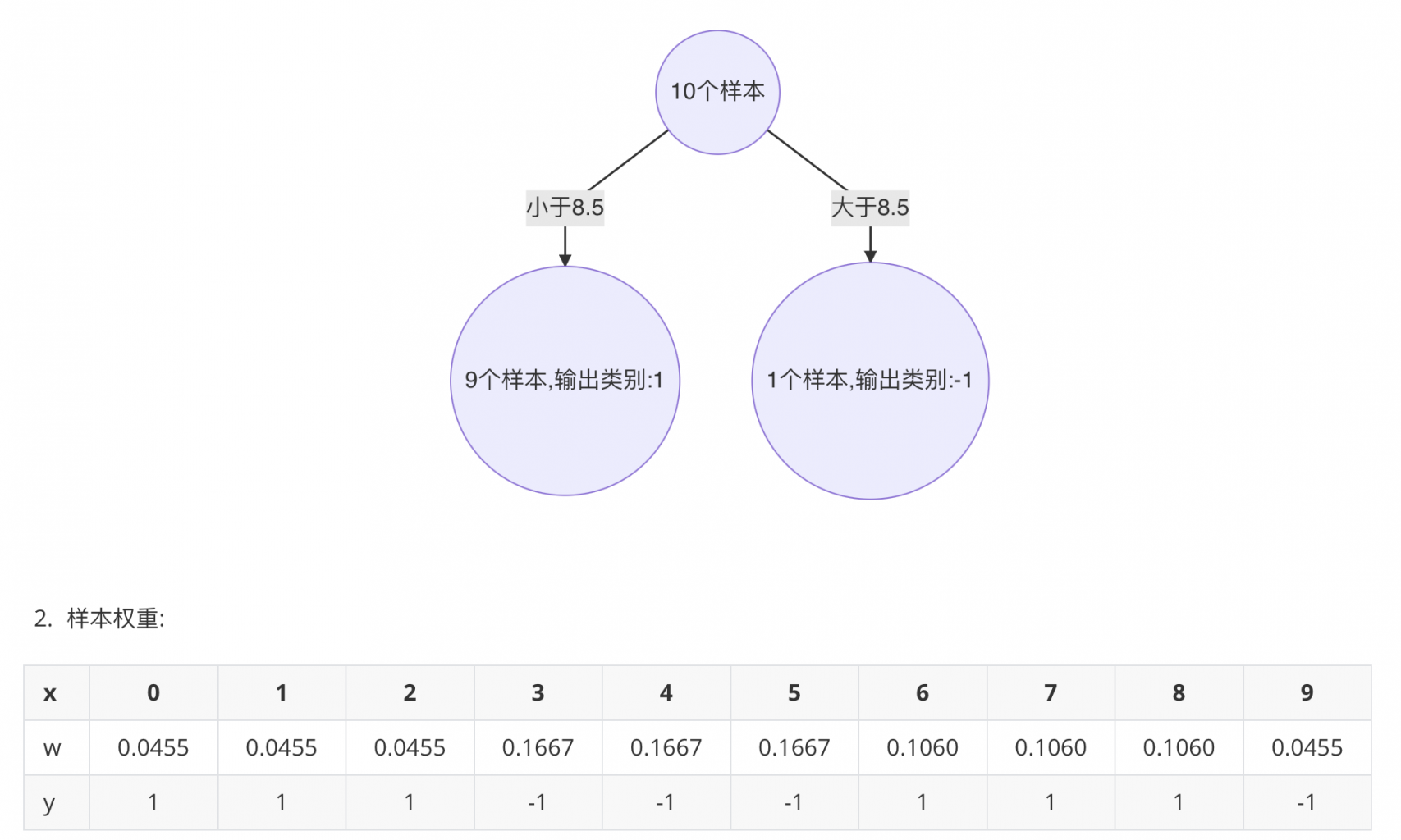
4. 构建第三个基学习器(决策树)
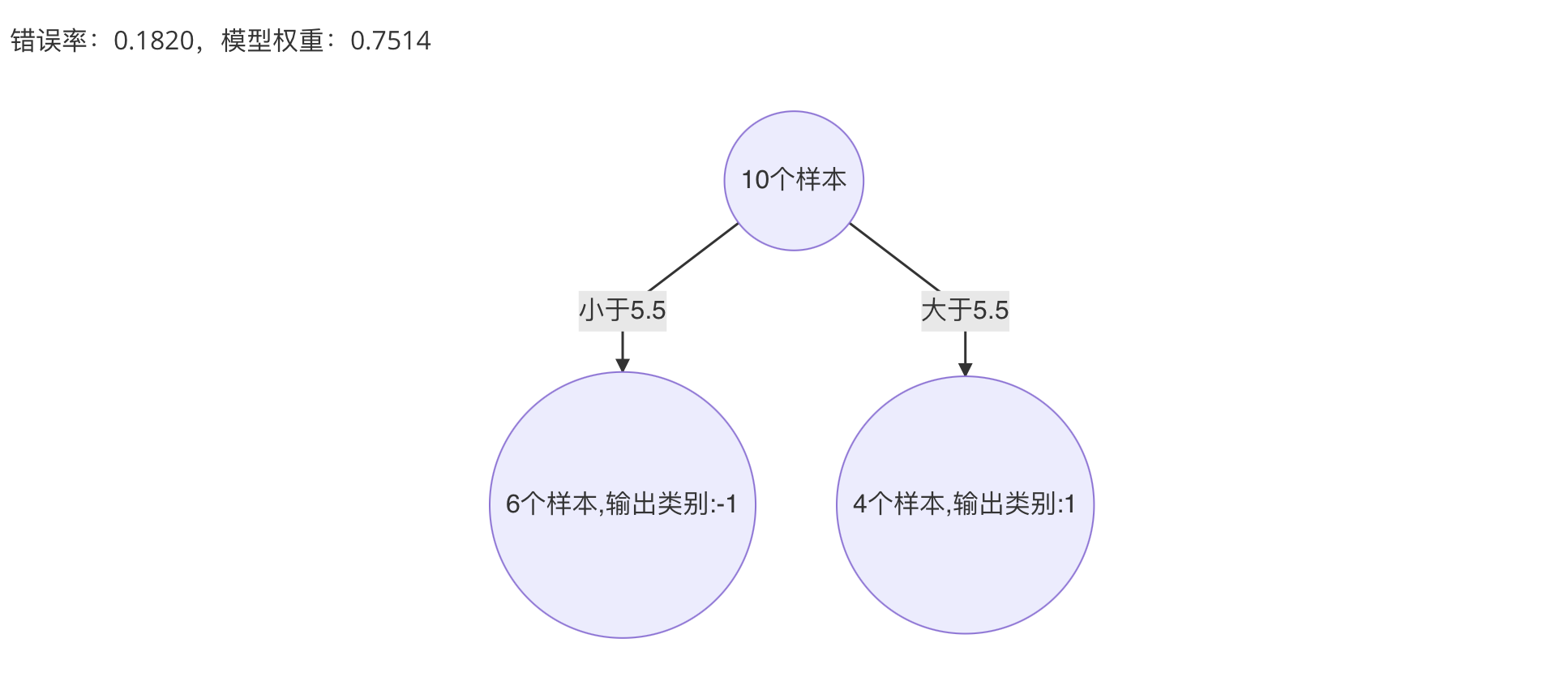
5. 最终强学习器

 冀公网安备13050302001966号
冀公网安备13050302001966号