
随机森林是 Bagging 的思想的一种实现,它使用决策树作为基础学习器。
- 随机森林概述
- 包外估计
- scikit-learn API
1. 随机森林概述
在关于随机森林的原始论文中,随机森林错误率取决于两个因素:
- 随机森林中任意两棵树之间的相关性越大则错误率越大。
- 随机森林中单个树的强度越高则森林错误率越低。
随机森林使用下面的方式训练具有差异性的基学习器:
- 每一个基决策树在特征集合中随机选择 k 个特征的子集进行训练,k 值一般为:log2d,d 表示特征数量
- 每一个基决策树通过有放回的抽样(booststrap sampling)产生训练集并训练
随机森林不会过拟合,我们可以根据需要运行任意数量的树。
随机深林简单、容易实现、计算开销小,它在很多现实任务中展现出强大的性能,被称为 “代表集成学习技术水平的方法”。随机森林的起始性能往往较差,随着基础学习器的增加,随机森林通常会收敛到更低的泛化误差。
随机森林如何将多个基学习器结合起来?
- 平均法。平均法分为简单平均法(simple averaging)和加权平均法(weighted averaging)。一般而言,基础学习器的性能相差较大时,使用加权平均法。而基础学习器性能相近时,使用简单平均法。
- 投票法。投票法分为多数投票法(majority voting)、相对投票法(plurality voting)和。多数投票法指的若某个分类票数过半,则预测为该分类,否则拒绝预测。相对投票法指的是预测为得票相对较多的分类,若多个分类得票数相同,则随机选择一个。
2. 包外估计
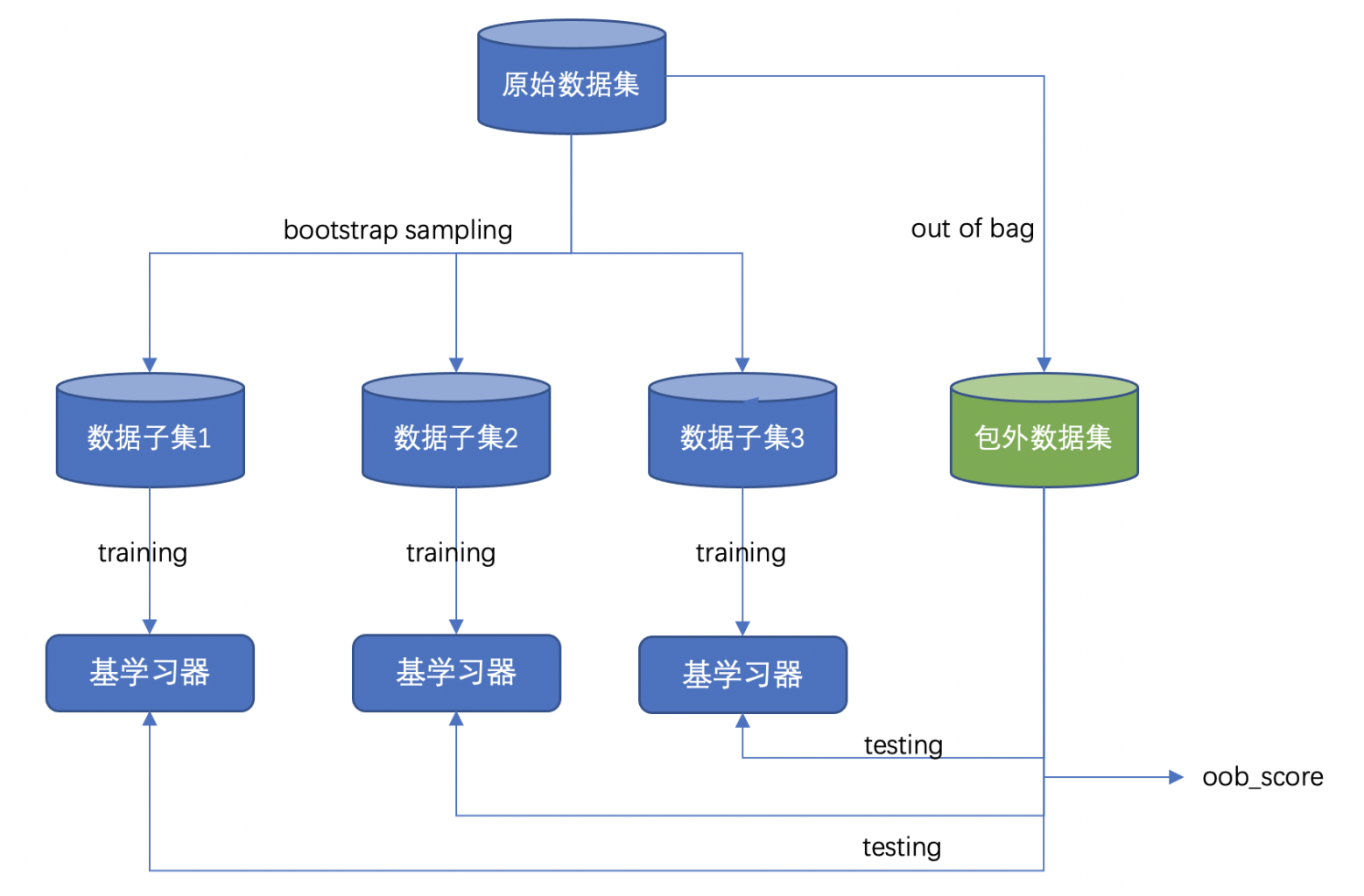
假如,要构建一个包含 m 棵树的随机深林,其步骤如下(从训练集角度):
- 对原始数据集通过 bootstrap sampling 产生 m 个数据子集
- 使用 m 个数据子集训练出 m 个决策树
- 在产生训练样本时,有大约 1/3 的数据集未参与基决策树训练,该部分数据为包外估计数据
使用包外数据集作为测试集,对每一棵基决策树进行评估,取所有树评分的均值作为包外误差估计 oob_score。
3. scikit-learn API
from sklearn.ensemble import RandomForestClassifier
RandomForestClassifier(n_estimators=10,
criterion=’gini’,
max_depth=None,
bootstrap=True,
random_state=None,
min_samples_split=2)
- n_estimators:integer,optional (default = 100)
- Criterion:string,optional (default =“gini”)
- max_depth:integer 或 None,可选(默认=无)
- max_features=”auto“, 每个决策树的最大特征数量
- If “auto”, then
max_features=sqrt(n_features). - If “sqrt”, then
max_features=sqrt(n_features)(same as “auto”). - If “log2”, then
max_features=log2(n_features). - If None, then
max_features=n_features.
- If “auto”, then
- bootstrap:boolean,optional(default = True), 是否在构建树时使用放回抽样
- min_samples_split 内部节点再划分所需最小样本数
- min_samples_leaf 叶子节点的最小样本数
- min_impurity_split: 节点划分最小不纯度
https://www.stat.berkeley.edu/~breiman/RandomForests/cc_home.htm
至此,本篇文章暂时结束。
 冀公网安备13050302001966号
冀公网安备13050302001966号