


scikit-learn 提供了 RandomForestClassifier 和 RandomForestRegressor 两个随机森林的实现,用于分类和回归任务。为了能够更好的使用随机森林,我们需要详细了解该实现的相关参数含义。
1. 基本参数
下面是 scikit-learn 1.3.0 随机森林实现的参数。
# 基学习器数量 n_estimators=100, # 评估分裂质量的指标 criterion="gini", # 决策树的最大深度 max_depth=None, # 内部节点再分裂所需的最小样本数 min_samples_split=2, # 叶节点中应包含的最小样本数 min_samples_leaf=1, # 叶节点样本权重的最小值 min_weight_fraction_leaf=0.0, # 每次分裂时考虑的特征数量 max_features="sqrt", # 限制叶节点的最大数量 max_leaf_nodes=None, # 节点分裂所需的最小不纯度减少量 min_impurity_decrease=0.0, # 是否对样本进行重采样 bootstrap=True, # 是否使用袋外样本来估计模型的泛化精度 oob_score=False, # 是否复用之前的训练得到的基学习器 warm_start=False, # 类别权重,用于处理不平衡数据 class_weight=None, # 最小代价复杂度剪枝 ccp_alpha=0.0, # 重采样样本数量 max_samples=None, # 控制详细程度,值越大,输出的信息越多 verbose=0, # 并行运行的作业数量 n_jobs=None, # 控制随机数生成的种子 random_state=None,
示例代码:
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
# bootstrap 参数: 是否使用有放回采样
def test01():
data = load_iris()
estimator = RandomForestClassifier(n_estimators=3, bootstrap=True, max_features=None)
estimator.fit(data.data, data.target)
print(estimator.estimators_)
plt.figure(figsize=(20, 10))
for index, model in enumerate(estimator.estimators_, start=1):
plt.subplot(1, len(estimator.estimators_), index)
plot_tree(model)
plt.show()
# warm_start 参数: 是否在原来基础上继续训练
def test02():
data = load_iris()
estimator = RandomForestClassifier(n_estimators=3, warm_start=True)
estimator.fit(data.data, data.target)
print(estimator.estimators_)
# 增加基学习器
estimator.n_estimators = 5
estimator.fit(data.data, data.target)
print(estimator.estimators_)
if __name__ == '__main__':
test01()
test02()
2. 袋外估计
随机森林在构建每个基学习器(决策树)时,会采用有放回的采样,这样就会存在一些未被抽到的样本集,称为袋外数据(oob 数据,out of bag)。
再次强调:oob 数据是从训练集中产生。
使用 oob 数据对随机森林进行评估得到的分数,称作袋外估计。
袋外估计的优点在于它可以在不使用额外的验证集的情况下,对随机森林模型的性能进行估计,有助于了解模型的泛化能力。
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestRegressor
from sklearn.datasets import fetch_california_housing
def test():
data = load_iris()
estimator = RandomForestClassifier(bootstrap=True, oob_score=True, n_jobs=-1, random_state=42)
estimator.fit(data.data, data.target)
# 使用准确率对 OOB 进行评估
print('oob score:', estimator.oob_score_)
data = fetch_california_housing(data_home='data')
estimator = RandomForestRegressor(bootstrap=True, oob_score=True, n_jobs=-1, random_state=42)
estimator.fit(data.data, data.target)
# 使用 R2 对 OOB 进行评估
print('oob score:', estimator.oob_score_)
if __name__ == '__main__':
test()
具体的计算过程是什么样的?
假设一个二分类问题,训练集有 0、1、2、3、4、5、6、7、8、9 共计 10 个样本,随机森林训练 3 个基学习器构成强学习器,每个基学习器的 oob 样本集如下:
- 第一个基学习器:0、4、5
- 第二个基学习器:2、5、6、7
- 第三个基学习器:0、4、5
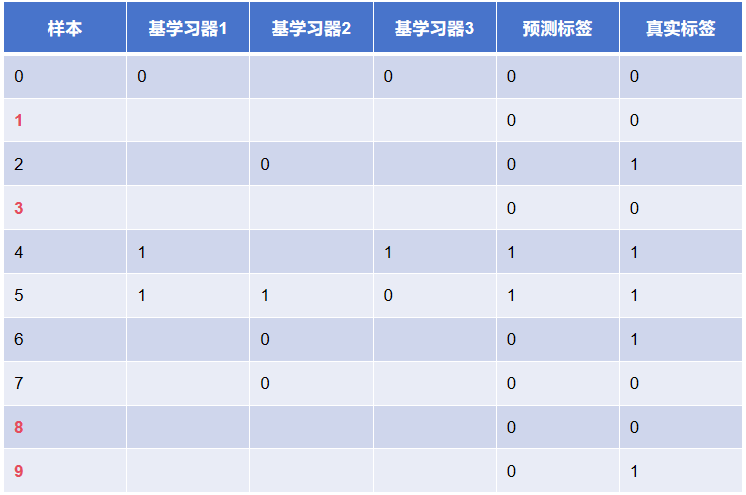
这里需要重点注意:
- scikit-learn 中随机森林实现中,oob 是基于所有的训练数据进行
- 即使某个样本不存在于 oob 中,也会参与到 oob score 的计算
- 太少的基学习器可能会导致某些训练样本无法有效参与 oob score 计算
最后,对于 oob score:
- 并非完全准确。虽然 oob score 可以提供一个性能评估的参考,但它并不是完全准确的。它只是对模型性能的一个近似估计,与使用独立验证集进行评估可能存在一定的差异。
- 评估分数不稳定。oob score 的计算结果可能会受到随机抽样的影响,具有一定的不稳定性。不同的随机抽样结果可能会导致不同的 oob score。为了减少这种不稳定性,可以多次计算 oob score 并取平均值,但这也会增加计算成本。
简言之:oob score 提供了对模型性能的近似估计,并不能代替验证集。


 冀公网安备13050302001966号
冀公网安备13050302001966号