


随机森林(Random Forest)能够用于分类和回归任务。通过两个应用案例来学习如何使用随机森林来解决分类和回归问题,以及算法的基本原理。
1. 算法使用
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import RandomForestRegressor
from sklearn.datasets import fetch_california_housing
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
def test01():
# 加载鸢尾花数据集
data = load_iris()
# 切分训练和验证集
X_train, X_test, y_train, y_test = (
train_test_split(data.data, data.target, test_size=0.2, random_state=42))
# 随机森林构建
estimator = RandomForestClassifier(n_jobs=-1)
# 随机森林训练
estimator.fit(X_train, y_train)
# 预测和输出
y_pred = estimator.predict(X_test[0].reshape(1, -1))
y_prob = estimator.predict_proba(X_test[0].reshape(1, -1))
print('y_pred:', y_pred, 'y_true:', y_test[0], 'y_prob:', y_prob)
# 随机森林评估
score = estimator.score(X_test, y_test)
print('acc: %.3f' % score)
def test02():
# 加载房价数据集
data = fetch_california_housing(data_home='data')
# 切分训练和验证集
X_train, X_test, y_train, y_test = (
train_test_split(data.data, data.target, test_size=0.2, random_state=42))
# 随机森林构建
estimator = RandomForestRegressor(n_jobs=-1)
# 随机森林训练
estimator.fit(X_train, y_train)
# 预测和输出
y_pred = estimator.predict(X_test[0].reshape(1, -1))
print('y_pred:', y_pred, 'y_true:', y_test[0])
# 随机森林评估
score = estimator.score(X_test, y_test)
print('r2: %.3f' % score)
if __name__ == '__main__':
test01()
test02()
2. 基本原理
随机森林通过构建多个决策树并将其结果进行整合来进行预测。训练和预测过程如下图所示:
训练时,首先从训练集数据中产生多个数据子集。然后使用训练子集训练处多个决策树(分类决策树或者回归决策树)
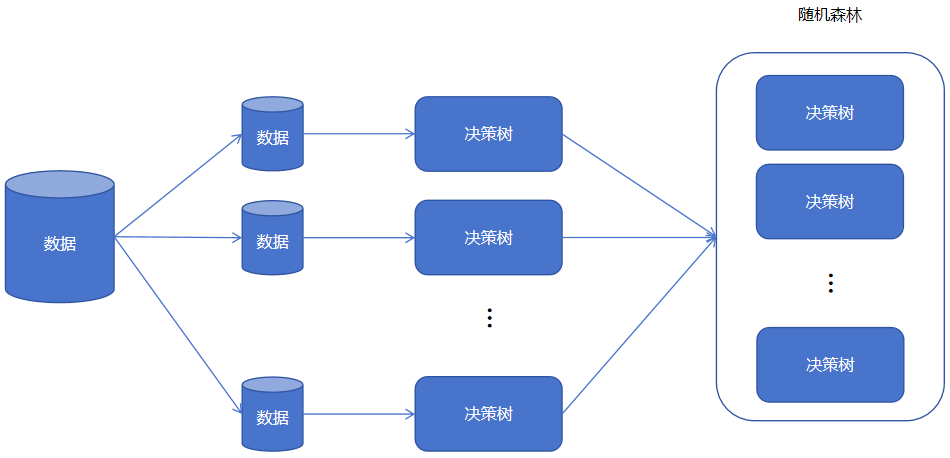
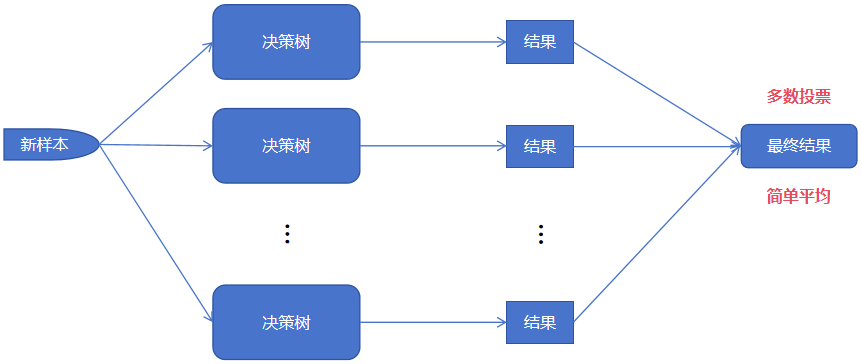
预测时,输入待预测的样本,由每个决策树(弱学习器、基学习器)给出预测结果。对于分类问题使用多数投票、回归问题使用简单平均来得出最终预测结果。


 冀公网安备13050302001966号
冀公网安备13050302001966号