


Scikit-Learn(sklearn)是一个用于机器学习的Python库,其中包含了大量用于分类、回归、聚类和其他机器学习任务的算法和工具。在sklearn中,决策树是其中的一个常用算法。下面,将会对决策树在 sklearn 中的 API 参数、属性、方法进行详细讲解。
1. 基本参数
- criterion:
- gini:表示使用基尼不纯度来选择最佳划分。
- entropy:表示使用信息增益来选择最佳划分。
- splitter:
- best:表示选择最佳的划分,即在每次划分时都找到最优的特征和特征值来进行划分。
- random:表示在随机的特征子集中选择最佳的划分。这可以提高模型的多样性和泛化能力。
- max_depth:树的最大深度。
- min_samples_split:节点分裂所需的最小样本数。
- min_samples_leaf:叶节点所需的最小样本数。
- min_weight_fraction_leaf:叶节点样本权重的最小加权分数。如果不是None,则输入数据的权重会影响叶节点的大小。
- max_features:在寻找最佳划分时考虑的最大特征数量。可以是整数、浮点数、字符串或None。
- None:考虑所有特征。
- int:每次分裂考虑的最大特征数量。
- float:表示考虑百分比的特征数量。
- sqrt:表示考虑sqrt(n_features)个特征。
- auto:与sqrt相同。
- log2:表示考虑log2(n_features)个特征。
- random_state:用于控制随机划分的随机状态。设置一个整数值可以使结果可复现。
- max_leaf_nodes:最大叶节点数量。如果为None,则不设置限制。
- min_impurity_decrease:分裂节点所需的最小不纯度减少量。如果分裂导致的不纯度减少小于这个值,则该分裂会被忽略。
2. 类别权重
class_weight 参数用于类别数据不平衡的场景。当类别不平衡时,算法可能会更加关注类别数量较多的样本,而忽略了类别数量较少的样本。通过为少数类别样本设置更高的权重,使得算法模型更加关注对少数样本的学习。
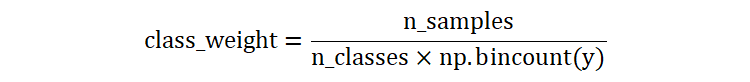
np.bincount(y): 计算每个类别的样本数量。n_samples:样本数量n_classes:类别数量
假设:有一个包含 100 个样本的数据集,分为 3 个类别。每个类别的样本数量分别为 [30, 50, 20]。
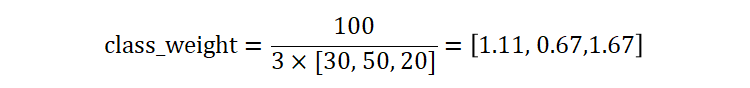
这意味着,类别1的样本权重是 1.11,类别2的样本权重是 0.67,类别3的样本权重是 1.67。
这种权重计算方式对于处理类别不平衡问题特别有用,因为它考虑了每个类别的样本数量,并为少数类分配更高的权重,从而使模型更关注少数类,提高模型在不平衡数据集上的性能。
3. 特征重要性
当我们构建好决策树之后,可以通过 feature_importances_ 属性来查看特征的重要程度。
色泽,根蒂,敲声,纹理,脐部,触感,好瓜 青绿,蜷缩,浊响,清晰,凹陷,硬滑,是 乌黑,蜷缩,沉闷,清晰,凹陷,硬滑,是 乌黑,蜷缩,浊响,清晰,凹陷,硬滑,是 青绿,蜷缩,沉闷,清晰,凹陷,硬滑,是 浅白,蜷缩,浊响,清晰,凹陷,硬滑,是 青绿,稍蜷,浊响,清晰,稍凹,软粘,是 乌黑,稍蜷,浊响,稍糊,稍凹,软粘,是 乌黑,稍蜷,浊响,清晰,稍凹,硬滑,是 乌黑,稍蜷,沉闷,稍糊,稍凹,硬滑,否 青绿,硬挺,清脆,清晰,平坦,软粘,否 浅白,硬挺,清脆,模糊,平坦,硬滑,否 浅白,蜷缩,浊响,模糊,平坦,软粘,否 青绿,稍蜷,浊响,稍糊,凹陷,硬滑,否 浅白,稍蜷,沉闷,稍糊,凹陷,硬滑,否 乌黑,稍蜷,浊响,清晰,稍凹,软粘,否 浅白,蜷缩,浊响,模糊,平坦,硬滑,否 青绿,蜷缩,沉闷,稍糊,稍凹,硬滑,否
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import plot_tree
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
import numpy as np
import warnings
warnings.filterwarnings('ignore')
def test():
data = pd.read_csv('data-3.csv')
inputs = data.iloc[:, :-1]
inputs = pd.get_dummies(inputs, dtype=np.float32)
labels = data.iloc[:, -1]
estimator = DecisionTreeClassifier(max_depth=2, random_state=42)
estimator.fit(inputs, labels)
plot_tree(estimator, node_ids=True, precision=5, feature_names=list(inputs.columns))
plt.show()
# 特征重要性
print(estimator.feature_importances_)
if __name__ == '__main__':
test()
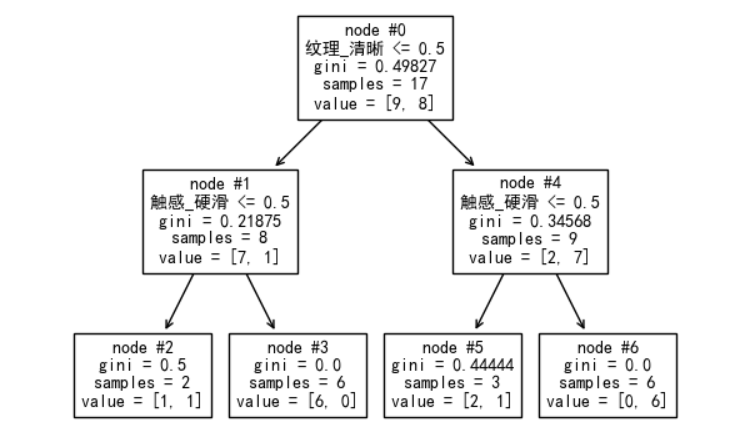
数据集中所有的特征如下:
['色泽_乌黑' '色泽_浅白' '色泽_青绿' '根蒂_硬挺' '根蒂_稍蜷' '根蒂_蜷缩' '敲声_沉闷' '敲声_浊响' '敲声_清脆' '纹理_模糊' '纹理_清晰' '纹理_稍糊' '脐部_凹陷' '脐部_平坦' '脐部_稍凹' '触感_硬滑' '触感_软粘']
这些特征如果没有出现在决策树构建过程中,则其重要性为 0。反之,则根据特征信息增益或基尼不纯度的降低程度,来计算其重要性。
纹理_清晰的不纯度下降程度:
使用该特征分裂前的加权不纯度:0.49827 * 17 = 8.47059
使用该特征分裂后的加权不纯度:0.21875 * 8 + 0.34568 * 9 = 4.86112
使用该特征分裂后的不纯度下降: 8.47059 – 4.86112 = 3.60947
触感_硬滑 的不纯度下降程度:
使用该特征分裂前的加权不纯度:0.21875 * 8 + 0.34568 * 9 = 4.86112
使用该特征分裂前的加权不纯度:0.5 * 2 + 0.0 * 6 + 0.44444 * 3 + 0.0 * 6 = 2.33332
使用该特征分裂后的不纯度下降:4.86112 – 2.33332 = 2.52780
标准化:
纹理_清晰:3.60947 / (3.60947 + 2.52780) = 0.58812
触感_硬滑:2.52780 / (3.60947 + 2.52780) = 0.41187


 冀公网安备13050302001966号
冀公网安备13050302001966号