


在学习决策树原理之前,我们先感性的了解下决策树的构建和推理过程、以及 API 的使用。
1. 分类决策树
分类决策树基于训练数据构建一个树状结构,每个节点代表一个特征,每个分支代表一个可能的答案,最终叶节点代表一个分类标签。
训练数据:
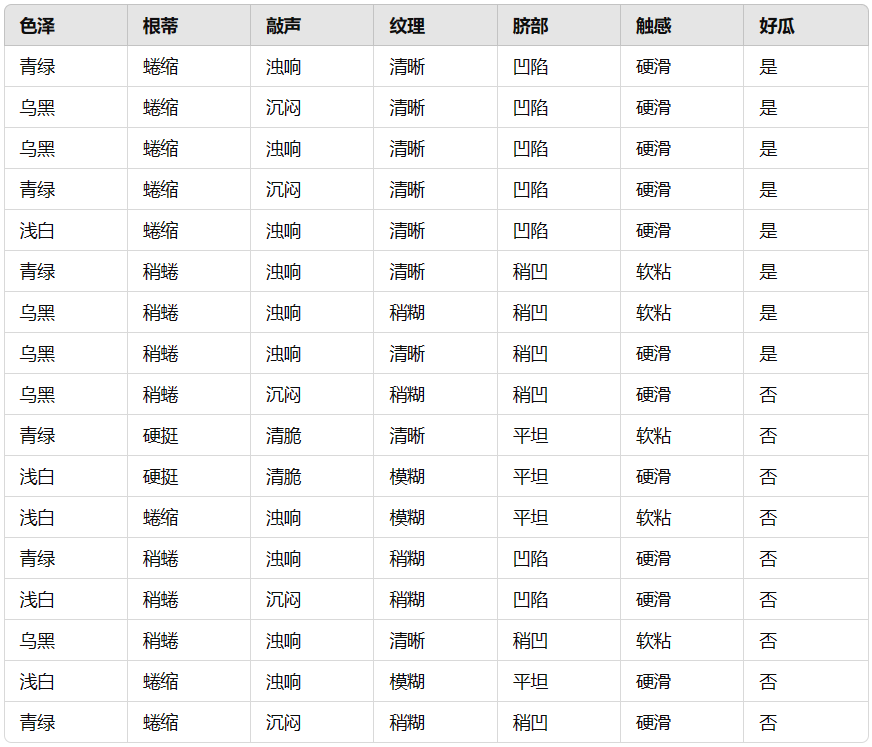
决策树构建:
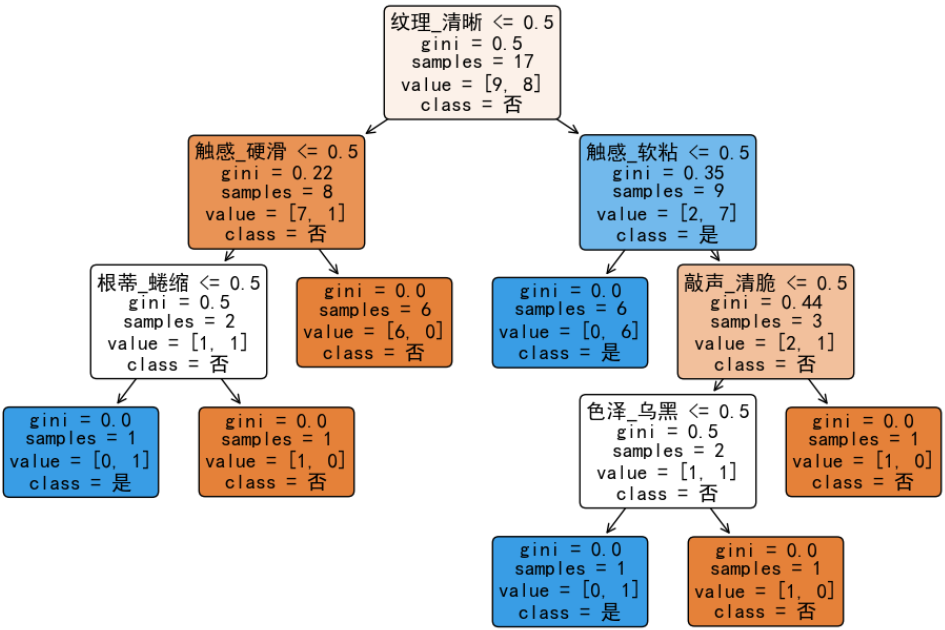
其中,0 代表否,1 代表是。
决策树预测:

2. 回归决策树
回归决策树基于训练数据构建一个树状结构,每个节点代表一个特征,每个分支代表一个预测走向,最终叶节点代表预测的结果。
训练数据:
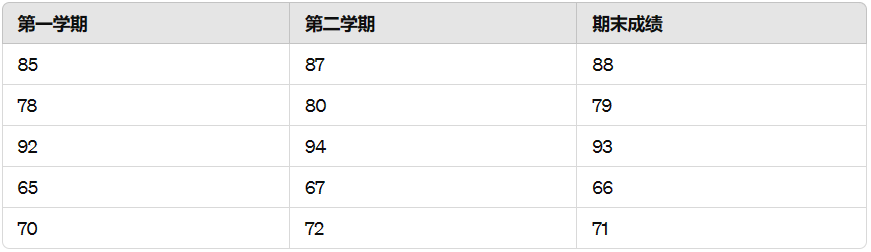
决策树构建:
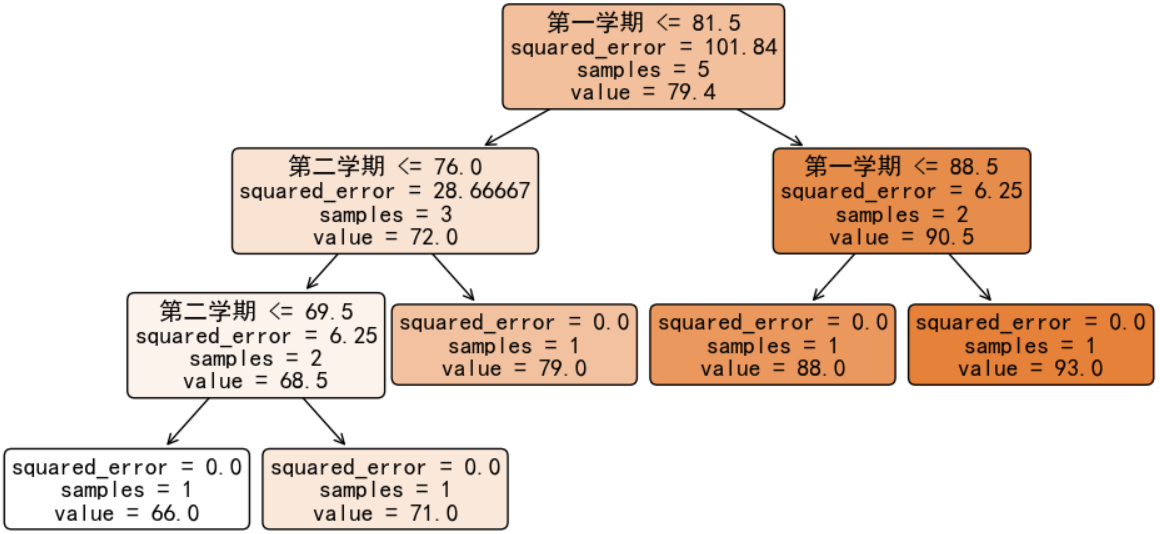
决策树预测:

3. 决策树使用
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import plot_tree
import pickle
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
import warnings
warnings.filterwarnings('ignore')
if __name__ == '__main__':
# 鸢尾花数据集
data = load_iris()
inputs = data['data']
labels = data['target']
# 决策树训练
estimator = DecisionTreeClassifier(random_state=42)
estimator.fit(inputs, labels)
# 决策树预测 - 输出标签
y_preds = estimator.predict(inputs)
# 决策树预测 - 输出概率
y_proba = estimator.predict_proba(inputs)
print(y_proba)
# 决策树评估
acc = estimator.score(inputs, labels)
print('Acc:', acc)
# 决策树存储
pickle.dump(estimator, open('estimator.pkl', 'wb'))
# 决策树加载
estimator = pickle.load(open('estimator.pkl', 'rb'))
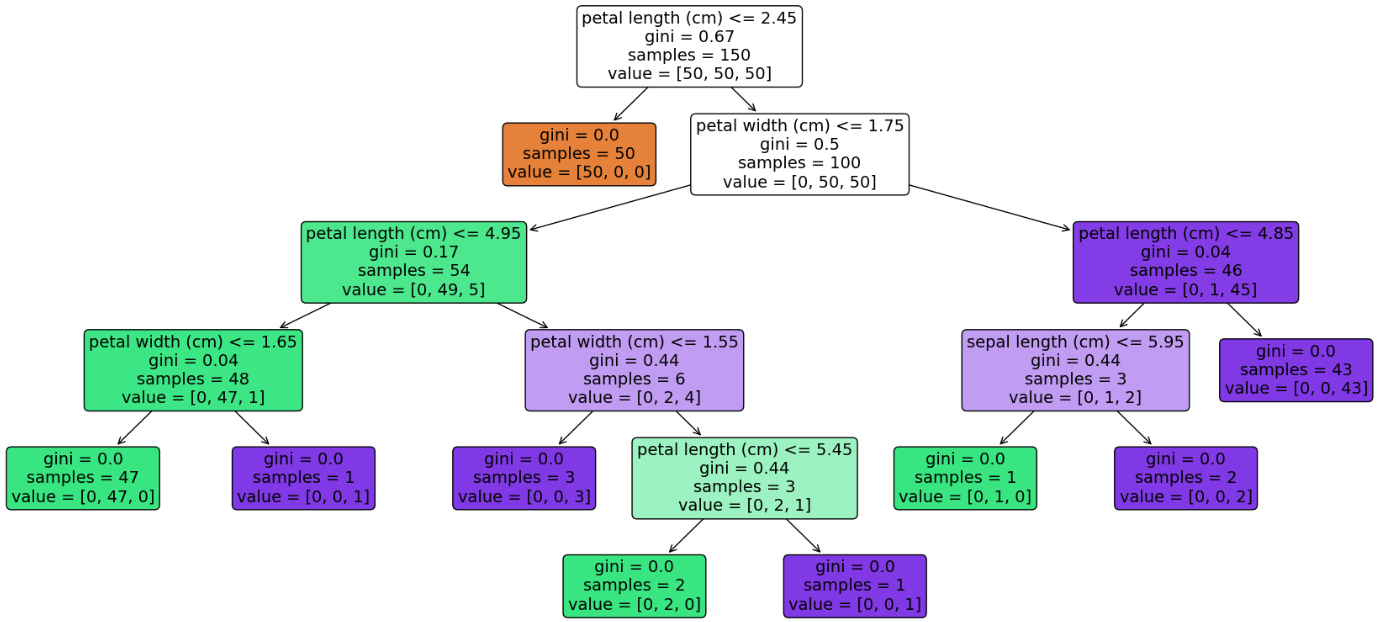
# 决策树可视化
plt.figure(figsize=(22, 10))
plot_tree(estimator, feature_names=data['feature_names'], filled=True, rounded=True, fontsize=14, precision=2)
plt.show()
决策树可视化:


 冀公网安备13050302001966号
冀公网安备13050302001966号