


Word2Vec 是 Google 在 2013 年推出的一种用于生成词向量的模型,它通过无监督学习的方式从大量文本数据中学习单词的语义关系。即:通过训练一个浅层的神经网络模型来学习如何将每个词转换为一个固定长度的向量。
这些向量能够定量地表示单词之间的相似性和关联性,这种转换使得原本抽象的词汇变得可以在数学上计算它们之间的相似度,进而挖掘出词汇之间的内在联系。
Word2Vec 是如何学习词向量的表示?
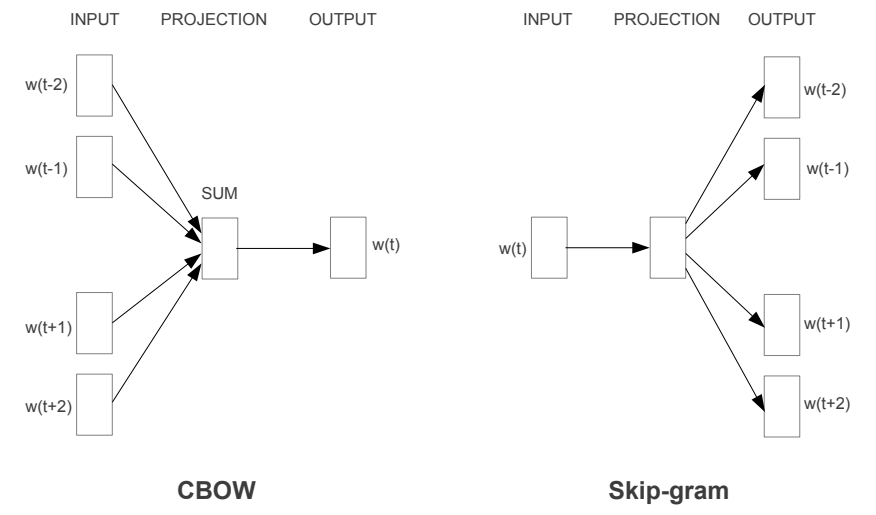
Word2Vec 通过跳字模型(Skip-Gram)和连续词袋模型(Continuous Bag of Words ,BOW)来学习词向量模型。我们也可以理解为是通过给神经网络设定的两种任务,通过反复执行该任务来实现词向量的训练。其中,Skip-Gram 模型输入中心词预测上下文词,而 CBOW 模型则是由上下文词预测中心词。
1. 网络结构
无论是采用连续词袋模型(CBOW)还是跳字模型(skip-gram),Word2Vec 网络结构都分为三部分:
- INPUT(输入): 输入的词是哪些,上下文词或者中心词。
- PROJECTION(投影层): 投影层实际上是 Word2Vec 模型的核心,负责将输入的词转换为一个向量。这个过程通常涉及到一个权重矩阵(输入矩阵),这个矩阵的每一行代表词汇表中每个词的嵌入向量。
- OUTPUT(输出): 输出目标词的预测概率。这个过程通常涉及到一个权重矩阵(输出矩阵),这个矩阵的每一列代表词表中的每个词的嵌入向量。用于计算输入词汇与词表中每个词的相关性。
- 训练的目标是希望目标词的预测概率越大越好。Word2Vec 认为距离相近的词具有更强的语义相关性,而距离较远的词则相关性较弱。
在 Word2Vec 模型中存在输入矩阵和输出矩阵。这两个矩阵的作用是在模型训练过程中用于捕获词汇之间关系的参数,具体如下:
- 输入矩阵:输入矩阵通常被用来表示单词的向量,每一行对应于一个单词的词向量,这个矩阵被称为W,维度是 V×N,其中 V 是词汇表的大小,N 是词向量的维度。
- 输出矩阵:输出矩阵同样每一列对应于一个单词的词向量,这个矩阵通常被称为 W’,维度也是V×N。
需要注意的是,在实际应用中,我们通常只使用输入矩阵作为词嵌入层,因为它足以代表单词之间的语义关系。然而,理论上讲,输出矩阵也包含了类似的信息,只是它通常不作为默认的词嵌入层使用。
2. 跳字模型
Skip-Gram 模型的目标是在给定一个中心词的情况下,预测它周围的上下文词汇。它通过最大化这些上下文词汇的条件概率来学习词向量。
例如:训练文本为:”a b c d e f g h”,设置窗口大小为 2,此时:
- 滑动窗口,则选中 a、b、c 词序列;
- 中心词为:a,上下文词:b、c
- 此时,将会产生 2 条训练样本:(a, b)、(a, c)
- 最大化上下文词 b、c 预测概率
此时,再滑动窗口:
- 中心词为:b,上下文词:a、c、d
- 此时,将会产生 3 条训练样本:(b, a)、(b, c)、(b, d)
- 最大化上下文词 a、c、d 预测概率
…以此类推
我们以 a、b、c、d、e 为例,如下图所示:

最终,使用将输入矩阵作为训练得到的词向量表示。
3. 连续词袋模型
与 Skip-Gram 模型不同,CBOW 试图从周围的上下文词汇中预测中心词汇。它通过最大化中心词汇的条件概率来学习词向量。
例如:训练文本为:”a b c d e f g h”,设置窗口大小为 2,此时:
- 滑动窗口,则选中 a、b、c 词序列;
- 中心词为:a,上下文词:b、c
- 此时,将会产生 1 条训练样本:(bc, a)
- 最大化中心词 a 预测概率
此时,再滑动窗口:
- 中心词为:b,上下文词:a、c、d
- 此时,将会产生 1 条训练样本:(acd, b)
- 最大化中心词 b 预测概率
…以此类推
我们以 a、b、c、d、e 为例,如下图所示:

最终,使用将输入矩阵作为训练得到的词向量表示。
4. 不足之处
SkipGram 和 CBOW 是实现词嵌入的常见技术,它通过词语共现来捕捉词语之间的语义关系。尽管在许多自然语言处理任务中表现出色,但它也存在一些不足之处:
- 计算效率低下:在训练时需要处理大量的数据,尤其是在构建大规模的词汇表时,需要耗费大量的计算资源和时间。
- 词汇表规模限制:性能在很大程度上受限于词汇表的规模。对于稀有词或者未登录词(Out of Vocabulary,OOV),往往难以产生有效的词嵌入。
- 上下文窗口大小选择困难:上下文窗口大小是一个需要手动选择的超参数。较小的窗口可能无法捕捉到词语之间的长距离语义关系,而较大的窗口则可能捕捉到过多的噪音信息。
- 相似词的表示不足:难以准确地捕捉到多义词的不同含义,以及一词多义的情况。
- 无法处理词序信息:算法只考虑了词语的共现关系,而没有考虑到词语的顺序信息。
虽然存在这些不足之处,但它仍然是一种有效的词嵌入技术,并且在许多自然语言处理任务中仍然被广泛使用。

 冀公网安备13050302001966号
冀公网安备13050302001966号