


Faiss(Facebook AI Similarity Search)是由 Facebook AI 团队开发的一个开源库,用于高效相似性搜索的库,特别适用于大规模向量数据集的存储与检索。
- 相似性搜索:Faiss 可以高效地搜索大规模向量集合中与查询向量最相似的向量。这对于图像检索、推荐系统、自然语言处理和大数据分析等领域非常有用。
- 多索引结构:Faiss 提供了多种索引结构,包括Flat、IVF、HNSW、PQ、LSH 索引等,以满足不同数据集和搜索需求的要求。
- 高性能:Faiss 可利用了多核处理器和 GPU 来加速搜索操作。
- 多语言支持:Faiss 支持 Python、C++ 语言。
- 开源:Faiss 是开源的,可以免费使用和修改,适用于学术研究和商业应用。
https://github.com/facebookresearch/faiss
# CPU 版本 pip install faiss-cpu -i https://pypi.tuna.tsinghua.edu.cn/simple # GPU 版本 https://anaconda.org/conda-forge/faiss-gpu conda install conda-forge::faiss-gpu
1. 基本使用
这一小节,快速通过一些代码案例来掌握 Faiss 向量数据库的使用方法。
https://github.com/facebookresearch/faiss/wiki/Faiss-indexes
import faiss
import numpy as np
np.random.seed(0)
# 1. 索引创建
def test01():
data = np.random.rand(10000, 256)
dim = 256
index = faiss.IndexFlatL2(dim) # 使用欧式距离计算相似度
index = faiss.IndexFlatIP(dim) # 使用点积计算相似度
index = faiss.index_factory(dim, "Flat", faiss.METRIC_L2)
index = faiss.index_factory(dim, "Flat", faiss.METRIC_INNER_PRODUCT)
# 添加向量
index.add(data)
# 搜索向量
query_vectors = np.random.rand(2, 256)
D, I = index.search(query_vectors, k=2)
print(D, I)
# 查询最近似向量的ID
I = index.assign(query_vectors, k=2)
print(I)
# 重建指定位置向量,并不是所有索引都支持该函数
# print(index.reconstruct(0))
# 删除指定 ID 数据
index.remove_ids(np.array([1, 2, 3]))
print(index.ntotal)
# 删除所有向量数据
index.reset()
print(index.ntotal)
# 存储索引
faiss.write_index(index, 'vectors1.faiss')
# 2. 向量 ID 映射
def test02():
# 默认情况下每一个向量都会分配一个连续的编号
# 现在希望能够给每一个向量指定一个 ID
index = faiss.IndexFlatIP(256)
index = faiss.IndexIDMap(index)
# 参数1:添加的向量
# 参数2:向量的编号
index.add_with_ids(np.random.rand(10000, 256), np.arange(10000, 20000))
print(index.ntotal)
if __name__ == '__main__':
test01()
test02()
2. 更快的索引
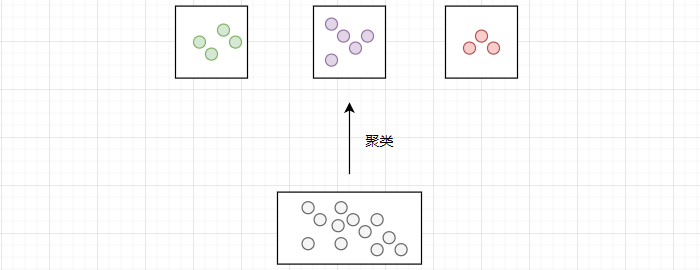
IndexFlat 索引是一种基于线性搜索的索引,它通过逐个计算与每个向量的相似度来进行搜索。在数据量较大的时候,搜索效率会较低。此时,我们可以使用 IndexIVFFlat 索引来提升搜索效率。它的原理如下:对于所有的向量进行聚类,相当于把所有的数据进行分类。当进行查询时,在最相似的 N 个簇中进行线性搜索。这就减少了需要进行相似度计算的数据量,从而提升搜索效率。
需要注意:这种方法是一种在查询的精度和效率之间平衡的方法。
import faiss
import numpy as np
import time
np.random.seed(0)
data = np.random.rand(1000000, 256)
ids = np.arange(0, 1000000)
query_vector = np.random.rand(1, 256)
def test01():
index = faiss.IndexFlatL2(256)
index = faiss.IndexIDMap(index)
# 添加向量
index.add_with_ids(data, ids)
# 搜索向量
s = time.time()
D, I = index.search(query_vector, k=2)
print('time:', time.time() - s)
print(D, I)
def test02():
# 第一个参数:量化参数
# 第二个参数:向量维度
# 第三个参数:质心数量
quantizer = faiss.IndexFlatL2(256)
index = faiss.IndexIVFFlat(quantizer, 256, 100)
# 增加搜索质心数量可以提高精确度,但是需要更多的时间
index.nprobe = 20
# 聚类计算质心
index.train(data)
# 添加向量
index.add_with_ids(data, ids)
# 搜索向量
s = time.time()
D, I = index.search(query_vector, k=2)
print('time:', time.time() - s)
print(D, I)
if __name__ == '__main__':
test01()
test02()
3. 更少的内存
前面学习的几个索引类型为了实现向量搜索,都需要将向量存储到 Faiss 中,当向量的数量较多时就会占用更多的内存。 这也影响了 Faiss 的应用。所以,为了减少内存的占用,我们就需要会存储的向量进行重新编码、压缩,使其占用更少的内存,从而能够容纳更多的向量。
量化技术可以使用较低精度的表示来近似向量数据,从而降低内存需求而又不牺牲准确性。 这对于大规模向量相似性搜索应用程序特别有用。
import os
import faiss
import numpy as np
import time
np.random.seed(0)
data = np.random.rand(1000000, 256)
ids = np.arange(0, 1000000)
query_vector = np.random.rand(1, 256)
def test01():
index = faiss.IndexFlatL2(256)
index = faiss.IndexIDMap(index)
# 添加向量
index.add_with_ids(data, ids)
# 搜索向量
s = time.time()
D, I = index.search(query_vector, k=2)
print('time:', time.time() - s)
print(D, I)
faiss.write_index(index, 'flat.faiss')
print(os.stat('flat.faiss').st_size)
def test02():
index = faiss.IndexFlatL2(256)
index = faiss.IndexIVFFlat(index, 256, 100)
index.nprobe = 4
index.train(data)
index.add_with_ids(data, ids)
s = time.time()
D, I = index.search(query_vector, k=2)
print('time:', time.time() - s)
print(D, I)
faiss.write_index(index, 'ivfflat.faiss')
print(os.stat('ivfflat.faiss').st_size)
def test03():
# 第一个参数:量化参数
# 第二个参数:向量维度
# 第三个参数:质心数量
# 第四个参数:子空间数量(或称为段数), 较大的值意味着将原始向量空间划分为更多的子空间进行量化,有助于减少量化误差,因为每个子空间都将被更精细地量化。
# 第五个参数:量化码本中码字的位数,每个段聚类的数量(8位256),决定了每个量化码字的精度,位数越多,每个码字能够表示的信息就越多,量化误差就越小。
quantizer = faiss.IndexFlatL2(256)
index = faiss.IndexIVFPQ(quantizer, 256, 100, 256, 10)
index.nprobe = 4
index.train(data)
index.add_with_ids(data, ids)
# 搜索向量
s = time.time()
D, I = index.search(query_vector, k=2)
print('time:', time.time() - s)
print(D, I)
faiss.write_index(index, 'ivfpq.faiss')
print(os.stat('ivfpq.faiss').st_size)
if __name__ == '__main__':
test01()
test02()
test03()
4. GPU 计算
传统 CPU 计算在处理大规模向量数据时往往效率低下,而 GPU 具有并行计算能力强、吞吐量高、延迟低等优势,可以显著提高向量相似度搜索的速度。例如,在 Faiss 官方提供的基准测试中,使用 GPU 计算的 Faiss 可以将向量相似度搜索的速度提高数十倍甚至数百倍。
import faiss
import numpy as np
def test():
# 创建标准的 GPU 资源对象,用它来管理GPU相关的计算资源。
res = faiss.StandardGpuResources()
# 在 CPU 创建索引
index_cpu = faiss.IndexFlatL2(256)
print(index_cpu)
# 将索引转到 GPU
# 参数1:GPU 使用资源
# 参数2:GPU 设备编号
# 参数3:转移的索引
index_gpu = faiss.index_cpu_to_gpu(res, 0, index_cpu)
print(index_gpu)
# 插入数据
index_gpu.add(np.random.rand(100000, 256))
# 向量搜索
D, I = index_gpu.search(np.random.rand(2, 256), k=2)
print(D)
print(I)
if __name__ == '__main__':
test()


 冀公网安备13050302001966号
冀公网安备13050302001966号