


对抗生成网络(Generative Adversarial Network)是一种深度学习模型,它通过两个神经网络生成器(Generator)和判别器(Discriminator)之间的对抗过程进行训练。通过这种对抗过程相互提升,从而使生成器能够生成非常逼真的数据。
- 生成器:负责生成假数据。它接受随机噪声作为输入,并尝试生成看起来尽可能真实的输出
- 判别器:负责区分输入的数据是来自训练集(真实数据)还是生成器(假数据)
对抗生成网络是一种非常强大的生成模型,在计算机视觉、自然语言处理、娱乐、艺术等多个领域都具有广泛的应用。
1. 数据处理
这段代码加载并处理 CIFAR-10 数据集中的图像,步骤如下:
- 加载数据:通过
glob和pickle从本地读取CIFAR-10训练数据集的多个数据批次文件。 - 图像转换:
- 使用
ToTensor将图像从 [0, 255] 范围转换为 [0, 1] 的张量。 - 使用
Normalize对图像进行标准化处理,均值为0.5,标准差为0.5。
- 使用
- 处理图像:将每个批次的图像数据重塑为适合处理的形状
(B, 3, 32, 32),然后对每张图像应用转换,得到处理后的图像数据。 - 保存图像数据:将处理后的图像数据保存为
images.pkl文件。 - 可视化:展示前16张处理后的图像,调整图像的范围并绘制出来。
import warnings
warnings.filterwarnings('ignore')
import torch
import torchvision
import torchvision.transforms as transforms
import glob
import pickle
import matplotlib.pyplot as plt
# https://www.cs.toronto.edu/~kriz/cifar.html
def demo():
fnames = glob.glob('data/cifar-10-batches-py/data_batch_*')
images = []
# ToTensor 将图像的像素值从 [0, 255] 转换为 [0, 1] 范围,并转换为张量类型
# Normalize 对图像的各个通道进行均值为 0.5,标准差为 0.5 的标准化操作
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
for fname in fnames:
batch_images = pickle.load(open(fname, 'rb'), encoding='bytes')
batch_images = batch_images[b'data']
# batch_labels = batch_images[b'labels']
# batch_images.shape 形状: (10000, 3072)
batch_images = batch_images.reshape(batch_images.shape[0], 3, 32, 32)
# batch_images.shape 形状: (B, H, W, C)
batch_images = batch_images.transpose(0, 2, 3, 1)
for image in batch_images:
# image shape: (32, 32, 3) -> (3, 32, 32)
image = transform(image)
images.append(image)
images = torch.stack(images)
# torch.Size([50000, 3, 32, 32])
pickle.dump(images, open('data/images.pkl', 'wb'))
# 图像信息
print('图像形状:', images.shape)
print('像素大小:', torch.min(images[0]), torch.max(images[1]))
for idx in range(16):
plt.subplot(4, 4, idx + 1)
image = images[idx]
image = (image + 1) / 2
# 当前图像形状: (C, H, W) 需要转换为显示图像形状: (H, W, C)
plt.imshow(image.permute(1, 2, 0))
plt.axis('off')
plt.show()
if __name__ == '__main__':
demo()
图像形状: torch.Size([50000, 3, 32, 32]) 像素大小: tensor(-1.) tensor(0.9922)

2. 生成器
这段代码实现了一个简单的生成对抗网络(GAN)中的生成器(Generator)部分,用于根据随机噪声生成图像。具体步骤如下:
- Generator定义:
Generator类继承自nn.Module,用于定义生成器网络。- 网络通过多个反卷积层(
ConvTranspose2d)逐步将输入的随机噪声(形状为(batch_size, latent_dim, 1, 1))变换为目标图像尺寸(如(batch_size, channels, 32, 32))。 - 每一层后面都接一个批量归一化层(
BatchNorm2d)和 LeakyReLU 激活函数,最后使用Tanh激活函数将输出映射到 [-1, 1] 的范围。
- 生成图像:
- 创建一个大小为
(2, 256, 1, 1)的随机噪声张量作为输入(这里2表示 batch size,256是噪声的维度)。 - 使用生成器模型生成图像。
- 创建一个大小为
- 可视化生成图像:
- 使用
matplotlib将生成的图像显示出来。图像的像素值映射到 [0, 1] 以便正确显示。
- 使用
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.nn.utils.spectral_norm as spectral_norm
class Generator(nn.Module):
"""根据输入噪声生成图像"""
def __init__(self, latent_dim=256, channels=3):
super(Generator, self).__init__()
self.latent_dim = latent_dim
self.model = nn.Sequential(
# 输入: (batch_size, latent_dim, 1, 1)
nn.ConvTranspose2d(latent_dim, 512, kernel_size=4, stride=1, padding=0, bias=False),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2, inplace=True),
# (batch_size, 512, 4, 4)
nn.ConvTranspose2d(512, 256, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2, inplace=True),
# (batch_size, 256, 8, 8)
nn.ConvTranspose2d(256, 128, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True),
# (batch_size, 128, 16, 16)
nn.ConvTranspose2d(128, 64, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2, inplace=True),
# (batch_size, 64, 32, 32)
nn.ConvTranspose2d(64, channels, kernel_size=3, stride=1, padding=1, bias=False),
nn.Tanh() # 输出范围 [-1, 1]
)
def forward(self, z):
return self.model(z)
if __name__ == '__main__':
# 1. 构造随机噪声
image_noise = torch.randn(2, 256, 1, 1)
# 2. 模型生成图像
estimator = Generator()
with torch.no_grad():
images = estimator(image_noise)
# 生成图像形状: (B, C, H, W)
print('图像形状:', images.shape)
# 3. 显示生成图像
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
for idx, image in enumerate(images, start=1):
plt.subplot(1, 2, idx)
# 显示图像形状: (H, W, C)
image = image.permute(1, 2, 0)
# 像素值映射到 [0, 1]
image = (image + 1) / 2
plt.imshow(image)
plt.show()
图像形状: torch.Size([2, 3, 32, 32])
3. 判别器
这段代码实现了生成对抗网络(GAN)中的判别器(Discriminator)部分,用于判断图像是否为伪造。具体步骤如下:
- Discriminator定义:
Discriminator类继承自nn.Module,用于定义判别器网络。- 网络使用多个卷积层(
Conv2d)逐步将输入图像(尺寸为(batch_size, 3, 32, 32))通过特征提取处理,最终输出一个表示图像为真实或伪造的概率。 - 每层卷积后面接一个 LeakyReLU 激活函数,最后通过
Sigmoid激活函数将输出映射到 [0, 1] 的范围,表示图像是“真实”还是“伪造”的概率。
- 计算伪造图像的判别概率:
- 生成一个形状为
(2, 3, 32, 32)的随机噪声图像(作为伪造图像)输入到判别器中。 - 通过判别器计算图像的判别概率,输出接近 1 表示图像更可能是真实的,接近 0 表示图像更可能是伪造的。
- 生成一个形状为
import torch
import torch.nn as nn
import torch.nn.functional as F
class Discriminator(nn.Module):
"""判断图像是否伪造"""
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=4, stride=2, padding=1), # 32x32 -> 16x16
nn.LeakyReLU(0.2),
nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1), # 16x16 -> 8x8
nn.LeakyReLU(0.2),
nn.Conv2d(128, 256, kernel_size=4, stride=2, padding=1), # 8x8 -> 4x4
nn.LeakyReLU(0.2),
nn.Conv2d(256, 512, kernel_size=4, stride=2, padding=1), # 4x4 -> 2x2
nn.LeakyReLU(0.2),
nn.Conv2d(512, 1, kernel_size=2, stride=1, padding=0), # 2x2 -> 1x1
nn.Sigmoid() # 输出概率
)
def forward(self, img):
return self.model(img)
if __name__ == '__main__':
# 1. 构造伪造图像(B, C, H, W)
image = torch.randn(2, 3, 32, 32)
# 2. 计算伪造概率
# 接近 1:表示判别器认为这张图像更可能是真实的(来自数据集)
# 接近 0:表示判别器认为这张图像更可能是伪造的(来自生成器)
estimator = Discriminator()
proba = estimator(image)
print(proba.shape)
print(proba.squeeze())
torch.Size([2, 1, 1, 1]) tensor([0.4952, 0.4981], grad_fn=<SqueezeBackward0>)
4. 对抗训练
这段代码实现了一个生成对抗网络(GAN)的训练过程,主要步骤如下:
- 数据加载:
- 加载保存的图像数据(
images.pkl),并使用DataLoader进行批量加载。
- 加载保存的图像数据(
- 模型初始化:
- 初始化生成器(
Generator)和判别器(Discriminator)模型,并将其移动到适当的设备(GPU 或 CPU)。
- 初始化生成器(
- 损失函数与优化器:
- 使用二元交叉熵损失(
BCELoss)作为生成器和判别器的损失函数。 - 使用 Adam 优化器分别优化生成器和判别器的参数。
- 使用二元交叉熵损失(
- 训练过程:
- 对于每个 epoch:
- 训练判别器:通过真实图像和生成器生成的伪造图像进行训练,使判别器能够区分真实和伪造的图像。
- 训练生成器:通过让生成器生成伪造图像并欺骗判别器,使生成器不断提升生成图像的质量。
- 更新损失并记录每个 epoch 的生成器和判别器的平均损失。
- 对于每个 epoch:
- 模型存储:
- 每隔 5 个 epoch 保存一次生成器和判别器的模型参数。
- 损失曲线绘制:
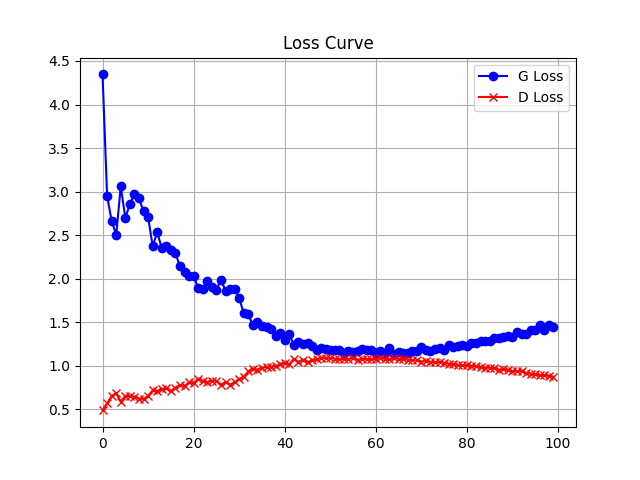
- 将训练过程中生成器和判别器的损失保存在文件中,并绘制损失变化曲线。
import shutil
import warnings
warnings.filterwarnings('ignore')
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
from generator import Generator
from discriminator import Discriminator
import torch
import torch.nn as nn
import torch.optim as optim
import pickle
import os
from tqdm import tqdm
def plot_loss_curve():
train_G_loss = pickle.load(open(f'model/train_G_loss.pkl', 'rb'))
train_D_loss = pickle.load(open(f'model/train_D_loss.pkl', 'rb'))
plt.plot(range(len(train_G_loss)), train_G_loss, label='G Loss', color='blue', marker='o')
plt.plot(range(len(train_D_loss)), train_D_loss, label='D Loss', color='red', marker='x')
plt.title('Loss Curve')
plt.legend()
plt.grid()
plt.show()
def train():
# 1. 数据加载
dataset = pickle.load(open('data/images.pkl', 'rb'))
dataloader = DataLoader(dataset, batch_size=64, shuffle=True)
# 2. 初始化模型
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
generator = Generator().to(device)
discriminator = Discriminator().to(device)
# 3. 定义损失函数和优化器
criterion = nn.BCELoss(reduction='mean')
optimizer_G = optim.Adam(generator.parameters(), lr=0.00017)
optimizer_D = optim.Adam(discriminator.parameters(), lr=0.00007)
# 4. 训练过程
train_G_loss, train_D_loss = [], []
for epoch in range(100):
progress = tqdm(range(len(dataloader)), ncols=100, desc='Epoch:%2d Loss G:%.5f Loss D:%.5f' % (0, 0, 0))
epoch_G_loss, epoch_D_loss, epoch_size = 0, 0, 0
for real_images in dataloader:
# 图像批次大小
batch_size = real_images.shape[0]
# ----------------------------------------------------
# 下面这一部分目的是训练判别器的判别能力
# ----------------------------------------------------
# 1. 生成器生成伪造图像和标签(0)
image_noise = torch.randn(batch_size, 256, 1, 1).to(device)
fake_images = generator(image_noise)
fake_labels = torch.zeros(batch_size, 1).to(device)
# 2. 数据集加载真实图像和标签(1)
real_images = real_images.to(device)
real_labels = torch.ones(batch_size, 1).to(device)
# 3. 判别器对图像伪造概率预测(1表示真实, 0表示伪造)
# 注意: 这里使用 fake_images 使用 detach
# 原因: 由于 fake_images 是由 generator 生成,如果不断开,则会更新 generator 的参数,
# 而此处我们只希望训练判别器,而不是生成器。简言之: 如果不断开,D 训练时,G 也会受到影响
fake_proba = discriminator(fake_images.detach())
real_proba = discriminator(real_images)
# 4. 计算判别器损失(正负样本损失)
fake_loss = criterion(fake_proba.squeeze(), fake_labels.squeeze())
real_loss = criterion(real_proba.squeeze(), real_labels.squeeze())
disc_loss = fake_loss + real_loss
# 5. 判别器参数更新
optimizer_D.zero_grad()
disc_loss.backward()
optimizer_D.step()
# ----------------------------------------------------
# 下面这一部分目的是训练生成器的生成能力,目标是让生成器骗过生成器
# ----------------------------------------------------
# 6. 让生成器骗过判别器
# 前面我们把伪造图像的标签设置为真是标签0,这里设置为假的标签1,目的是为了欺骗判别器
fake_labels = torch.ones(batch_size, 1).to(device)
# 7. 计算判别器将伪造图像当做真图像的概率
# 概率越大,说明判别器越预测错误,被欺骗的程度越高,损失越低
# 概率越小,说明判别器越预测准确,被欺骗的程度越高,损失越高
fake_proba = discriminator(fake_images)
gene_loss = criterion(fake_proba.squeeze(), fake_labels.squeeze())
# 8. 生成器参数更新
optimizer_G.zero_grad()
gene_loss.backward()
optimizer_G.step()
# 9. 记录损失变化
epoch_size += batch_size
epoch_G_loss += gene_loss.item() * batch_size
epoch_D_loss += disc_loss.item() * batch_size
epoch_avg_G_loss = epoch_G_loss / epoch_size
epoch_avg_D_loss = epoch_D_loss / epoch_size
progress.set_description('Epoch:%2d Loss G:%.5f Loss D:%.5f' % (epoch + 1, epoch_avg_G_loss, epoch_avg_D_loss))
progress.update()
progress.close()
train_G_loss.append(epoch_avg_G_loss)
train_D_loss.append(epoch_avg_D_loss)
# 10. 模型存储
if (epoch + 1) % 5 == 0:
save_path = f'model/{epoch + 1}/'
if os.path.exists(save_path) or os.path.isdir(save_path):
shutil.rmtree(save_path)
os.mkdir(save_path)
pickle.dump(generator, open(save_path + 'generator.pkl', 'wb'))
pickle.dump(discriminator, open(save_path + 'discriminator.pkl', 'wb'))
# 11. 打印训练损失变化曲线
pickle.dump(train_G_loss, open('model/train_G_loss.pkl', 'wb'))
pickle.dump(train_D_loss, open('model/train_D_loss.pkl', 'wb'))
plot_loss_curve()
# watch -n 10 nvidia-smi
if __name__ == '__main__':
train()
5. 图像生成
这段代码的主要功能是根据不同版本的生成器(generator.pkl)生成图像,并将它们展示出来。具体步骤如下:
- 设备选择:
- 判断是否有可用的 GPU,如果有,则使用 GPU,否则使用 CPU。
- 循环加载模型:
- 从
model/文件夹中加载不同版本的生成器模型(每 5 个 epoch 保存一个模型),从第 5 个 epoch 到第 100 个 epoch 之间的每 5 个模型(即model_5,model_10, …,model_100)。
- 从
- 生成图像:
- 为每个加载的生成器生成一个批次的噪声(大小为 16,噪声维度为 256)。
- 使用生成器将噪声转换为图像(通过
generator(image_noise))。
- 显示生成图像:
- 将生成的 16 张图像按 4×4 网格排列,并使用
matplotlib显示出来。 - 图像的像素值被调整到 [0, 1] 范围,并以灰度图的方式展示。
- 将生成的 16 张图像按 4×4 网格排列,并使用
import warnings
warnings.filterwarnings('ignore')
from generator import Generator
import pickle
import torch
import matplotlib.pyplot as plt
def generate_images():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
for model_id in range(5, 101, 5):
# 加载图像生成器
generator = pickle.load(open(f'model/{model_id}/generator.pkl', 'rb')).to(device)
# 生成图像噪声
batch_size, noise_dim = 16, 256
image_noise = torch.randn(batch_size, noise_dim, 1, 1).to(device)
# 根据噪声生成图像
with torch.no_grad():
images = generator(image_noise)
# 显示生成的图像
for idx, image in enumerate(images, start=1):
plt.subplot(4, 4, idx)
image = image.permute(1, 2, 0).cpu()
# 像素映射到 [0, 1]
image = (image + 1) / 2
plt.imshow(image, cmap='gray')
plt.axis('off')
plt.show()
if __name__ == '__main__':
generate_images()


 冀公网安备13050302001966号
冀公网安备13050302001966号