
Sentence Transformers 是由 Hugging Face 维护的开源 Python 库,通过深度学习模型捕捉文本的语义信息,转换为数值向量表示。基于这些向量可以实现语义相似度计算、文本聚类、信息检索、情感分析和问答系统等 NLP 任务。由于其简单易用的 API 和高效的处理能力,已成为自然语言处理领域的重要工具。
pip install sentence-transformers
1. 句子相似度
从 https://www.sbert.net/docs/pretrained_models.html 查看可用的预训练模型。下面例子加载的预训练模型是 paraphrase-multilingual-MiniLM-L12-v2,模型信息如下:

我们使用余弦相似度来计算两个输入 sentence 的相似度,示例代码:
from sentence_transformers import SentenceTransformer
import sentence_transformers.util as util
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def test():
# 模型构建
model = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2', device=device)
# 计算单个句子向量
sentence_embedding1 = model.encode('我是中国人')
sentence_embedding2 = model.encode('我是生活在北京的中国人')
similarity = util.cos_sim(sentence_embedding1, sentence_embedding2)
print('相似度:', '%.2f' % similarity)
# 计算多个句子向量
sentences = ['我是中国人', '我是生活在北京的中国人']
sentence_embeddings = model.encode(sentences)
similarity = util.cos_sim(sentence_embeddings[0], sentence_embeddings[1])
print('相似度:', '%.2f' % similarity)
if __name__ == '__main__':
test()
程序执行结果:
相似度: 0.89 相似度: 0.89
2. 语义检索
首先将语料中的 N 个 sentence 计算出词向量表示,根据 query 词向量从语料中计算语义相近的 K 个 sentence。

sentence_transformers.util.semantic_search function performs a cosine similarity search between a list of query embeddings and a list of corpus embeddings. It can be used for Information Retrieval / Semantic Search for corpora up to about 1 Million entries.
参数如下:
- query_embeddings – A 2 dimensional tensor with the query embeddings.
- corpus_embeddings – A 2 dimensional tensor with the corpus embeddings.
- query_chunk_size – Process 100 queries simultaneously. Increasing that value increases the speed, but requires more memory.
- corpus_chunk_size – Scans the corpus 100k entries at a time. Increasing that value increases the speed, but requires more memory.
- top_k – Retrieve top k matching entries.
- score_function – Function for computing scores. By default, cosine similarity.
返回值:
- Returns a list with one entry for each query. Each entry is a list of dictionaries with the keys ‘corpus_id’ and ‘score’, sorted by decreasing cosine similarity scores.
示例代码:
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
from sentence_transformers.util import semantic_search
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def test():
# 模型构建
model = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2', device=device)
# 语料文本
corpus = ['我是中国人', '我是生活在北京的中国人', '我今天去公园玩了很长时间', '前天老王去他邻居家玩了']
# 查询文本
query = '我是个生活在北京的中国平民'
# 语料词向量
corpus_embeddings = model.encode(corpus, convert_to_tensor=True, device=device)
# 语料词向量
query_embedding = model.encode(query, convert_to_tensor=True, device=device)
# 查询前 K 个语义相近的 sentence
results = semantic_search(query_embeddings=query_embedding,
corpus_embeddings=corpus_embeddings,
top_k=2,
score_function=cos_sim)
# 打印输出结果
print('搜索结果:', results)
search_sentences = [corpus[result['corpus_id']] for result in results[0]]
print('搜索结果:', search_sentences)
if __name__ == '__main__':
test()
程序执行结果:
搜索结果: [[{'corpus_id': 1, 'score': 0.9394572377204895}, {'corpus_id': 0, 'score': 0.8251887559890747}]]
搜索结果: ['我是生活在北京的中国人', '我是中国人']
搜索加速可以使用 ElsticSearch、Annoy、Faiss、hnswlib
https://www.sbert.net/examples/applications/semantic-search/README.html#speed-optimization
3. 微调模型
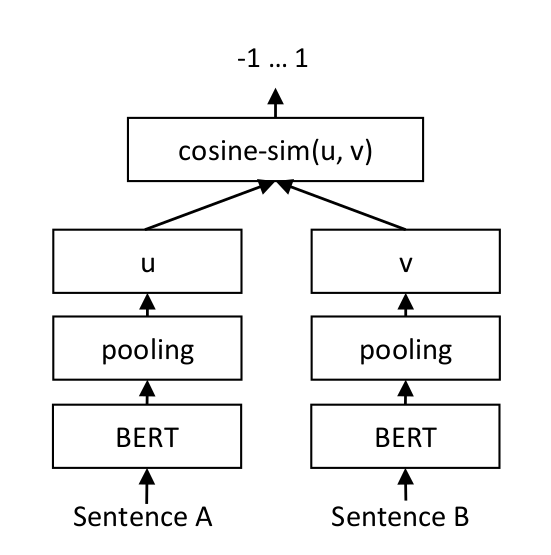
https://www.sbert.net/docs/training/overview.html
from sentence_transformers import SentenceTransformer
from sentence_transformers import InputExample
from sentence_transformers import losses
from torch.utils.data import DataLoader
from sentence_transformers import evaluation
if __name__ == '__main__':
# Define the model. Either from scratch of by loading a pre-trained model
model = SentenceTransformer('bert-base-chinese')
pooling_model = models.Pooling(word_embedding_model.get_word_embedding_dimension())
# Define your train examples. You need more than just two examples...
train_examples = [InputExample(texts=['My first sentence', 'My second sentence'], label=0.8),
InputExample(texts=['Another pair', 'Unrelated sentence'], label=0.3)]
# Define your train dataset, the dataloader and the train loss
train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=16)
train_loss = losses.CosineSimilarityLoss(model)
sentences1 = ['This list contains the first column',
'With your sentences',
'You want your model to evaluate on']
sentences2 = ['Sentences contains the other column',
'The evaluator matches sentences1[i] with sentences2[i]',
'Compute the cosine similarity and compares it to scores[i]']
scores = [0.3, 0.6, 0.2]
evaluator = evaluation.EmbeddingSimilarityEvaluator(sentences1=sentences1,
sentences2=sentences2,
scores=scores)
# Tune the model
model.fit(train_objectives=[(train_dataloader, train_loss)],
epochs=1,
warmup_steps=100,
evaluator=evaluator,
evaluation_steps=500)
# Save
model.save('model')
 冀公网安备13050302001966号
冀公网安备13050302001966号