


在自然语言处理(NLP)任务中,自动评估文本生成质量是一个核心问题。例如,在机器翻译、自动摘要、文本生成等任务中,我们需要度量生成文本与参考文本的相似度。Rouge(Recall-Oriented Understudy for Gisting Evaluation)是一种常用的文本评估指标,特别适用于评估摘要生成质量。
Rouge 主要衡量生成文本与参考文本之间的 n-gram 匹配情况,常见的 Rouge 变体包括 Rouge-N、Rouge-L、Rouge-W 和 Rouge-SU 等。
- Rouge-N:计算 n-gram(n 连续词)的匹配情况,常见的是 Rouge-1 和 Rouge-2。
- Rouge-L:基于最长公共子序列(LCS),适用于衡量顺序相似度。
- Rouge-W:是 Rouge-L 的加权版本,考虑了较长连续匹配的权重。
- Rouge-SU:计算 Skip-Bigram(跳跃二元组)的匹配情况,同时引入单字 unigram。
pip install rouge
1. Rouge-N
Rouge-N 是 ROUGE 评测方法中的一种,主要用于 自动摘要、机器翻译、文本生成 等任务。它衡量生成文本(候选文本)和参考文本(标准答案)之间的 N-gram 重叠率,即计算它们的 相似度。
N-gram 是自然语言处理(NLP)中的一个概念,表示由 连续 N 个词(或字符) 组成的片段。例如,对于文本 ["我", "是", "中国", "人"]
- 1-gram(Unigram):每个单独的词为单位,
["我", "是", "中国", "人"] - 2-gram(Bigram): 两个连续的词为单位,
["我是", "是中国", "中国人"] - 3-gram(Trigram):三个连续的词为单位,
["我是中国", "是中国人"]
Rouge-N 主要计算 参考文本和自动生成文本之间的 N-gram 重叠率

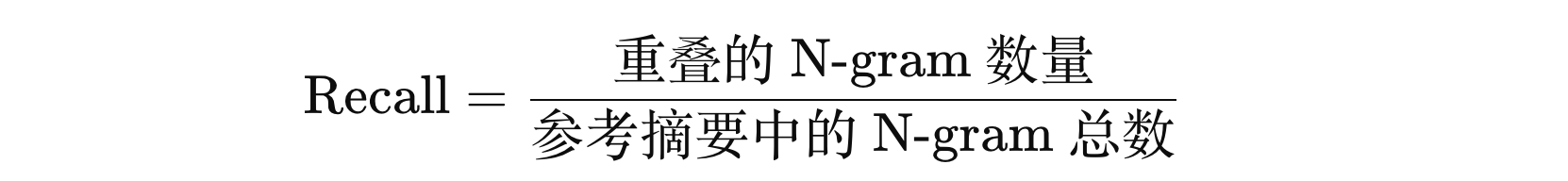

假设我们得到的生成文本和参考文本如下:
- 机器摘要(Hypothesis):
"我是中国人" - 标准摘要(Reference):
"我是个地地道道堂堂正正的中国人"
对文本进行分词分词(基于 Jieba)
- 机器摘要(Hyp):
["我", "是", "中国", "人"] - 标准摘要(Ref):
["我", "是", "个", "地地道道", "堂堂正正", "的", "中国", "人"]
我们进行 1-gram 相关的统计:
- 匹配内容:
["我", "是", "中国", "人"] - 机器摘要:
["我", "是", "中国", "人"] - 标准摘要:
["我", "是", "个", "地地道道", "堂堂正正", "的", "中国", "人"]

我们进行 2-gram 相关的统计:
- 匹配内容:
["我是", "中国人"] - 机器摘要:
["我是", "是中国", "中国人"] - 标准摘要:
["我是", "是个", "个地地道道", "地地道道堂堂正正", "堂堂正正的", "的中国", "中国人"]

从上面例子,可以看到 Rouge-N 是一个关注 Recall 的自动摘要评估指标。
注意:使用 Rouge-N 应该去除停用词后再进行评估。
示例代码:
import rouge
import jieba
import pandas as pd
def test01():
my_rouge = rouge.Rouge(metrics=["rouge-1", "rouge-2"], stats=["r", 'p'])
# hyps: 生成摘要
# refs: 参考摘要
hyp = jieba.lcut('我是中国人')
ref = jieba.lcut('我是个地地道道堂堂正正的中国人')
print('hyp 分词:', hyp)
print('ref 分词:', ref)
scores = my_rouge.get_scores(hyps=[' '.join(hyp)], refs=[' '.join(ref)])
print(scores)
if __name__ == '__main__':
test01()
[{'rouge-1': {'r': 0.5, 'p': 1.0}, 'rouge-2': {'r': 0.2857142857, 'p': 0.666666666}}]
前面计算时候,我们假设参考摘要只有一个,如果多于一个参考摘要的话,机器生成摘要的 Rouge-N 得分如本计算?其实,就是取得分最高作为当前机器生成摘要的得分。
2. Rouge-L
Rouge-L 是 ROUGE 评测方法中的一种,主要用于自动摘要、机器翻译、文本生成等任务。它通过计算生成文本(候选文本)和参考文本(标准答案)之间的最长公共子序列(LCS, Longest Common Subsequence)来评估它们的相似度。
公共最长子序列(LCS)是指给定两个序列(例如字符串),我们从这两个序列中找出一个最长的子序列,使得该子序列在两个序列中都出现,并且元素的顺序保持不变。例如:
- A = “ABCBDAB”
- B = “BDCABB”
它们的最长公共子序列是 “BCAB”,因为 “BCAB” 是这两个字符串中都出现的最长子序列。
由此可以看出 Rouge-L 关注的是词序的匹配,而不仅仅是词的共现。具体来说,Rouge-L 使用 LCS 的长度来计算召回率和精确率,并通过 F1 分数来综合评估生成文本与参考文本的相似度。
这种方法的优点在于它能够捕捉到句子级别的词序信息,而不需要预定义的 N-gram 长度。然而,它也有局限性,即只计算一个最长子序列,忽略了其他可能的子序列的影响



我们进行 1-gram 相关的统计:
- LCS内容:
["我", "是", "中国", "人"] - 机器摘要:
["我", "是", "中国", "人"] - 标准摘要:
["我", "是", "个", "地地道道", "堂堂正正", "的", "中国", "人"]


from rouge import Rouge
import jieba
import logging
jieba.setLogLevel(logging.CRITICAL)
def demo():
rouge = Rouge(metrics=['rouge-l'], stats=['r', 'p'])
hyps = [' '.join(jieba.lcut('我是中国人'))]
refs = [' '.join(jieba.lcut('我是一个地地道道堂堂正正的中国人'))]
scores = rouge.get_scores(hyps=hyps, refs=refs, avg=False)
print(scores)
if __name__ == '__main__':
demo()
程序执行结果:
[{'rouge-l': {'r': 0.5, 'p': 1.0}}]
3. Rouge-X
Rouge 系列的评估方法中,除了以上两者还包括 Rouge-W、Rouge-S、Rouge-SU 等,但是这些方法在大多数的 rouge 实现中并不包含。这是因为:
- 相比基本的 Rouge-N、Rouge-L 要更复杂,增加计算的复杂度。
- Rouge-N(尤其是 Rouge-1 和 Rouge-2)已经能够涵盖大部分的评估需求
- 尽管这些评测指标在某些情况下可能有优势,但它们并不是评估文本生成任务的普遍标准
- Rouge-N 是最常见且被广泛接受的评估方式,其他的更复杂的 Rouge 指标可能存在一些实现上的不一致或难以标准化的地方,导致它们没有被广泛实现。
经过实验,Rouge-1、Rouge-L 在非常短的摘要中表现比较好,比如:标题级别。Rouge-2、Rouge-L 在单文档摘要中表现很不错。
 冀公网安备13050302001966号
冀公网安备13050302001966号