
多标签分类是指每个样本可以被分配到多个类别中,即:可以拥有多个标签。比如:某条新闻既可以是军事类新闻、也可以是政治类新闻。
在评估多标签分类模型时,我们使用的是样本平均精确率、样本平均召回率和样本平均 F1 分数。
y_true = [['好评', '中评'], ['好评', '中评', '差评'], ['好评', '差评'], ['中评', '差评'], ['中评', '好评']] y_pred = [['中评', ], ['好评', '差评'], ['中评', ], ['好评', '差评'], ['中评', '好评']]
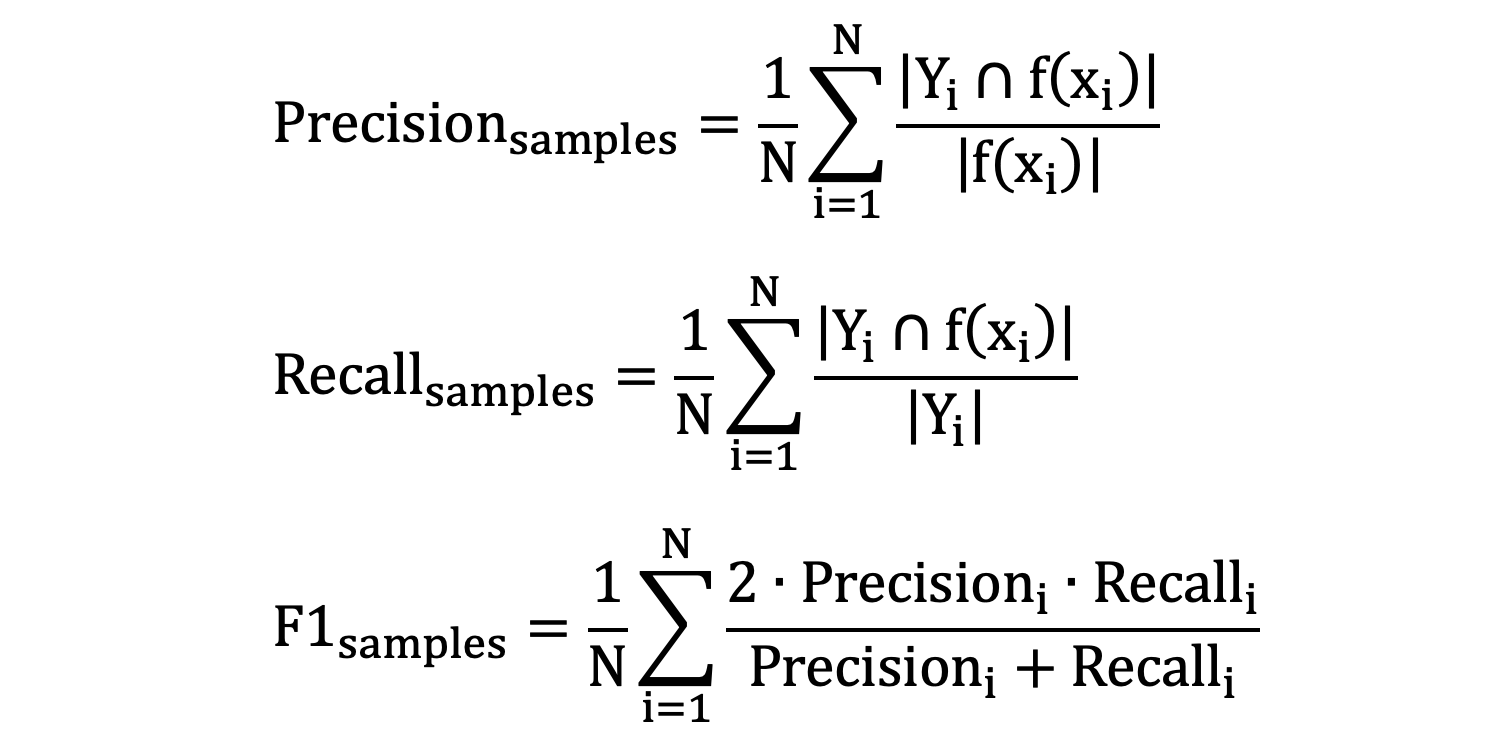
- \(N\) 表示样本数量
- \(Y_{i}\) 表示第 i 个样本真实标签集合
- \(f(x_{i})\) 表示第 i 个样本预测的标签集合
- \(Precision_{i}\) 表示第 i 个样本的精确度
- \(Recall_{i}\) 表示第 i 个样本的召回率
接下来,计算每个样本的精确度、召回率、f1-score 值如下:
样本1: 精确度:1.0 召回率:0.5 F1-score:0.6666666666666666 样本2: 精确度:1.0 召回率:0.6666666666666666 F1-score:0.8 样本3: 精确度:0.0 召回率:0.0 F1-score:0.0 样本4: 精确度:0.5 召回率:0.5 F1-score:0.5 样本5: 精确度:1.0 召回率:1.0 F1-score:1.0
计算每个指标的样本平均值:
精确度:0.7 召回率:0.5333333333333333 F1-score:0.5933333333333334
使用示例:
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
from sklearn.preprocessing import MultiLabelBinarizer
import pandas as pd
if __name__ == '__main__':
# 真实和预测标签
y_true = [['好评', '中评'], ['好评', '中评', '差评'], ['好评', '差评'], ['中评', '差评'], ['中评', '好评']]
y_pred = [['中评', ], ['好评', '差评'], ['中评', ], ['好评', '差评'], ['中评', '好评']]
# 注意:必须对标签进行重新编码
mlb = MultiLabelBinarizer()
y_true = mlb.fit_transform(y_true)
y_pred = mlb.transform(y_pred)
print(mlb.classes_)
print(y_true)
print(y_pred)
result = precision_score(y_true, y_pred, average='samples')
print('精确率:\t\t', result)
result = recall_score(y_true, y_pred, average='samples')
print('召回率:\t\t', result)
result = f1_score(y_true, y_pred, average='samples')
print('f1-score:\t', result)
['中评' '好评' '差评'] [[1 1 0] [1 1 1] [0 1 1] [1 0 1] [1 1 0]] [[1 0 0] [0 1 1] [1 0 0] [0 1 1] [1 1 0]] 精确率: 0.7 召回率: 0.5333333333333333 f1-score: 0.5933333333333334
 冀公网安备13050302001966号
冀公网安备13050302001966号