
ELECTRA(Efficiently Learning an Encoder that Classifies Token Replacements Accurately)是一种用于自然语言处理(NLP)的预训练模型,旨在提升模型训练效率和性能。ELECTRA 模型由 Google Research 提出,相比传统的 BERT 模型,它采用了一种不同的预训练策略。
Paper:https://openreview.net/pdf?id=r1xMH1BtvB
1. 训练目标
ELECTRA的核心思想是通过 生成替换与判别任务(Replaced Token Detection,RTD) 来进行训练。具体来说,ELECTRA 的训练过程由以下两部分组成:
- 生成器(Generator):通过最大似然估计训练,目的是生成与上下文相关的替代标记
- 判别器(Discriminator):通过二元分类任务训练,学习区分真实标记和生成器生成的替代标记

在上图中, 将文本 the chef cooked the meal 中的某些词随机替换为 [mask],然后输入到 Generator ,并由 Generator 将其中的 [MASK] 预测(替换)为其他的词。例如,将第一个 [mask] 替换为原词 the,而第二个 [mask] 则替换为另一个词 ate,这样就得到了一条训练样本。Discriminator 的任务是对生成器生成的文本进行判断,预测 token 是是 original 还是 replaced。
ELECTRA 的损失函数由生成器损失和判判别器损失组成。生成器的损失函数是基于Masked Language Model 的损失函数。具体来说,生成器的任务是预测被掩盖的 token,因此其损失函数为 MLM 损失函数:
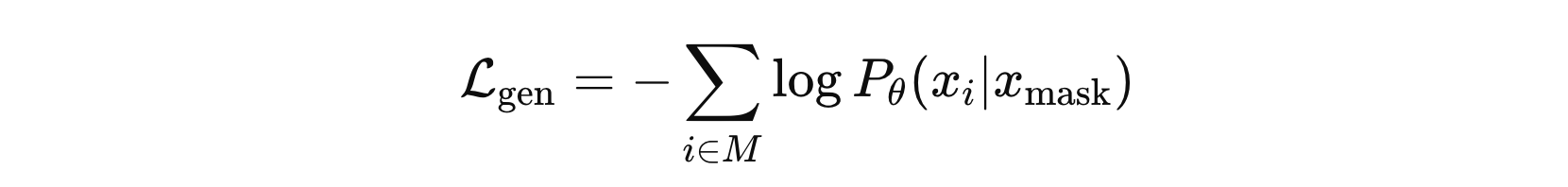
其中,\( M \) 是掩蔽的词位置,\( x_{mask} \) 是掩蔽后的词,\( \theta \) 是生成器的参数,\( P_{\theta}(x_{i}|x_{mask}) \) 是生成器预测的概率。
生成器生成的 假词 将会被标记为负样本,原始词 则作为正样本。判别器的损失就是预测每个token 被替换过的概率。
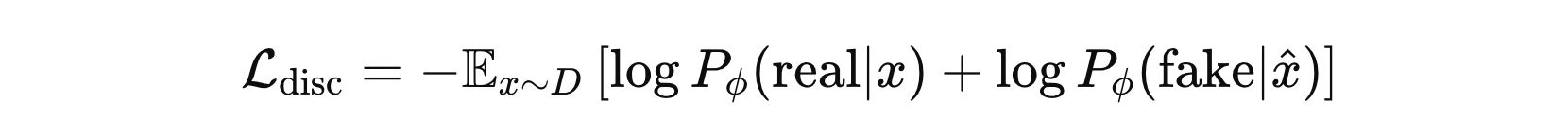
其中,\( D \) 是输入数据,\( \hat{x} \) 是被替换的 token,\( \phi \) 是判别器的参数,\( P_{\phi}(real|x) \) 和 \(P_{\phi}(fake|\hat{x}) \) 分别是判别器对 真token和 假token 的预测概率。
ELECTRA 的总损失函数是生成器损失和判别器损失的加权和:

其中,\( \lambda \) 是一个超参数,控制生成器损失和判别器损失之间的相对重要性。
通过上面损失的计算过程,我们发现在 Electra 中,并没有采用对抗性训练(Adversarial Training),虽然 Electra 的结构看起来类似于 GAN(生成对抗网络),但它实际上不是一个真正的对抗式训练模型。
在 GAN 中,生成器和判别器是 对抗性 的,生成器试图生成更逼真的样本,而判别器试图区分真实样本和生成样本。生成器的训练目标是 欺骗判别器,而判别器的训练目标是 不被欺骗。
在 Electra 中,生成器的训练目标是 预测被 mask 的 token,而不是欺骗判别器。生成器的损失函数是基于其预测的 token 与真实 token 的交叉熵损失,与判别器的任务无关。判别器的训练目标是 区分原始 token 和替代 token,而不是与生成器进行对抗。
2. 下游任务
Electra 采用了一个较小的生成器(Generator)和一个更强大的判别器(Discriminator)。生成器的能力受限,它不会完全准确地预测真实 token,而是生成接近但带有一定偏差的 token,从而构造用于训练的伪数据。判别器的任务是学习如何区分真实 token 和生成器生成的伪 token,这一过程中,判别器会学习到更丰富的 token 表征能力。
换句话说,生成器的主要作用是辅助训练,为判别器提供学习样本,而判别器则通过学习 token 之间的细微差异来获取更好的表示能力。在下游任务中,我们通常基于判别器学习到的文本表征进行微调,以适应不同的任务需求。
英文语料预训练:
https://huggingface.co/google/electra-small-discriminator
https://huggingface.co/google/electra-base-discriminator
中文语料预训练:
https://huggingface.co/hfl/chinese-electra-small-discriminator
https://huggingface.co/hfl/chinese-electra-base-discriminator
https://huggingface.co/hfl/chinese-electra-180g-small-discriminator
https://huggingface.co/hfl/chinese-electra-180g-base-discriminator
https://huggingface.co/hfl/chinese-electra-180g-small-ex-discriminator
接下来,使用 chinese-electra-small-discriminator 来微调一个简单的文本分类任务。
from transformers import ElectraForSequenceClassification
from transformers import ElectraTokenizer
import torch
from transformers import Trainer
from transformers import TrainingArguments
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
def demo():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
modelpath = 'chinese-electra-small-discriminator'
tokenizer = ElectraTokenizer.from_pretrained(modelpath)
estimator = ElectraForSequenceClassification.from_pretrained(modelpath, num_labels=2).to(device)
samples = pd.read_csv('comments.csv').dropna()
x_train, x_valid = train_test_split(samples, test_size=0.2, shuffle=True, stratify=samples['label'])
x_train, x_valid = x_train.to_numpy(), x_valid.to_numpy()
def get_dataset(data):
all_data = []
for label, input in data:
input = tokenizer.encode_plus(input,
truncation=True,
max_length=512,
return_tensors=None,
return_token_type_ids=False,
return_attention_mask=False)
input['labels'] = torch.tensor(label)
all_data.append(input)
return all_data
x_train = get_dataset(x_train)
x_valid = get_dataset(x_valid)
training_args = TrainingArguments(
output_dir='results',
eval_strategy='epoch',
save_strategy='epoch',
logging_strategy='no',
learning_rate=5e-5,
optim='adamw_torch',
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
num_train_epochs=10,
weight_decay=0.01,
disable_tqdm=True,
)
def do_metric(eval_pred):
# # 获取预测的 logits 和真实标签
logits, labels = eval_pred
predictions = logits.argmax(axis=-1)
acc = accuracy_score(labels, predictions)
return {'acc': acc}
trainer = Trainer(model=estimator,
args=training_args,
train_dataset=x_train,
eval_dataset=x_valid,
compute_metrics=do_metric,
processing_class=tokenizer)
trainer.train()
tokenizer.save_pretrained('saved_model')
estimator.save_pretrained('saved_model')
if __name__ == '__main__':
demo()
 冀公网安备13050302001966号
冀公网安备13050302001966号