
下面的是具体的训练代码和小说生成代码。
1. 训练代码
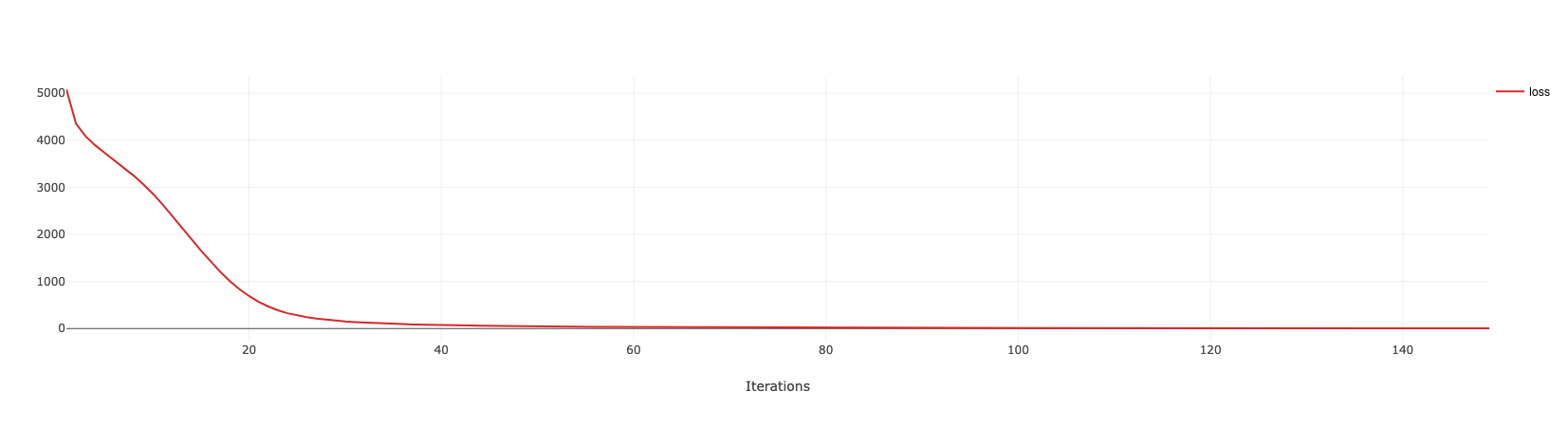
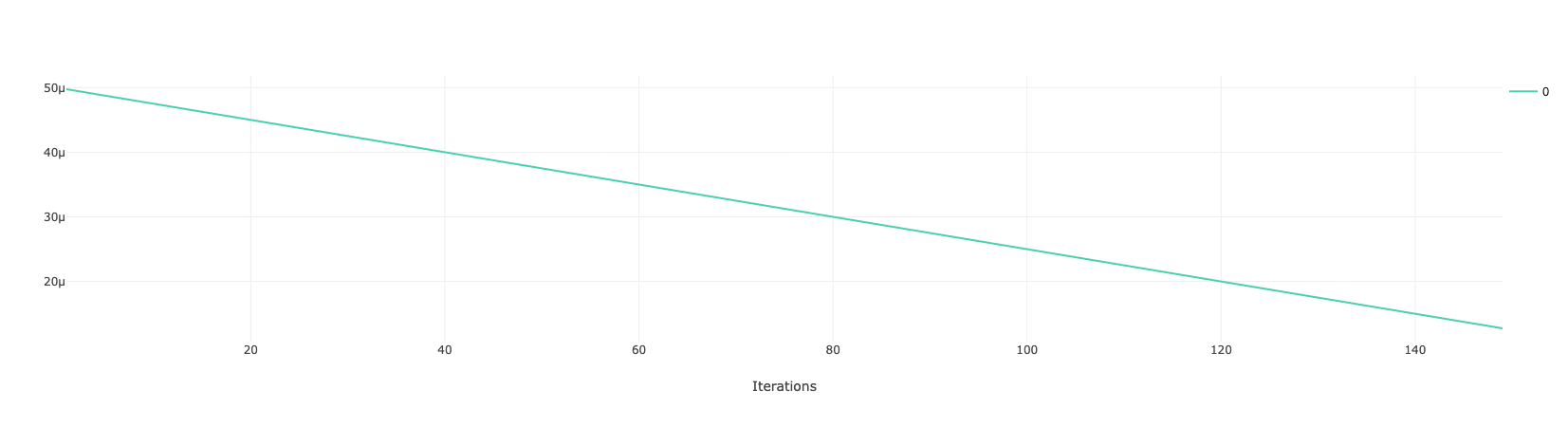
训练过程会输出一个 epoch 的总损失,以及每个 epoch 结束时使用的学习率。注意,下面代码运行时,不可以将 main 函数中的代码放到单独的 train 函数中,这是因为在一些其他的处理函数、事件函数中需要用到一些 main 中直接定义的对象,放到 train 函数的话,将不能直接访问到这些对象。具体的训练信息如下:
- num_epoch = 200
- learning rate = 5e-5
- optimizer = AdamW
- batch_size = 1
每个 epoch 结束会记录一次损失。另外,train_step_accuml 和 train_step_nornal 为单步的训练函数,前者使用的是累加梯度的方式,累加 16 迭代,进行一次参数更新。后者则是每次迭代结束即更新参数。
import math
from torch.utils.data import DataLoader
from torch.utils.data import TensorDataset
import pickle
from ignite.engine import Engine, Events, supervised_training_step
from ignite.contrib.handlers import PiecewiseLinear
from ignite.contrib.handlers import ProgressBar
from ignite.contrib.handlers.clearml_logger import ClearMLLogger
from ignite.handlers import Checkpoint
from transformers import BertTokenizer
import torch
from transformers import GPT2LMHeadModel
from transformers import GPT2Config
from transformers import AdamW
from datasets import load_from_disk
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
def collate_handler(batch_data):
param = {'padding': 'longest',
'return_token_type_ids': False,
'return_tensors': 'pt',
'add_special_tokens': False}
data_inputs = tokenizer(batch_data, **param)
model_inputs = {'input_ids': data_inputs['input_ids'].to(device),
'attention_mask': data_inputs['attention_mask'].to(device),
'labels': data_inputs['input_ids'].to(device),}
return model_inputs
def train_step_accuml(engine, batch_data):
outputs = model(**batch_data)
loss = outputs.loss / accumulation_steps
loss.backward()
if engine.state.iteration % accumulation_steps == 0 or \
engine.state.iteration % engine.state.epoch_length == 0:
optimizer.step()
optimizer.zero_grad()
return loss
def train_step_nornal(engine, batch_data):
outputs = model(**batch_data)
loss = outputs.loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
return loss
def model_score(engine):
return -engine.total_loss
def record_loss(engine):
engine.total_loss += engine.state.output.item()
def on_epoch_start(engine):
engine.total_loss = 0
def on_epoch_end(engine):
loss = engine.total_loss
lr = optimizer.param_groups[0]["lr"]
print('loss: %.5f lr: %.8f' % (loss, lr))
engine.total_loss = 0
if __name__ == '__main__':
accumulation_steps = 16
trainer = Engine(train_step_nornal)
tokenizer = BertTokenizer.from_pretrained('model')
config = GPT2Config(vocab_size=tokenizer.vocab_size)
model = GPT2LMHeadModel(config=config).to(device)
num_epoch = 200
optimizer = AdamW(model.parameters(), lr=5e-5)
batch_size = 1
# 事件
trainer.add_event_handler(Events.ITERATION_COMPLETED, record_loss)
trainer.add_event_handler(Events.EPOCH_STARTED, on_epoch_start)
# 检查点
to_save = {'model': model, 'optimizer': optimizer, 'trainer': trainer}
param = {'to_save': to_save, 'save_handler': 'temp', 'n_saved': 2, 'score_function': model_score}
trainer.add_event_handler(Events.EPOCH_COMPLETED, Checkpoint(**param))
# 进度条
progress = ProgressBar()
progress.attach(trainer)
# 记录日志
logger = ClearMLLogger(project_name="Novel Generation", task_name='GPT2 for Novel Generation')
logger.attach_output_handler(trainer, Events.EPOCH_COMPLETED, tag='training', output_transform=lambda _: {"loss": trainer.total_loss})
logger.attach_opt_params_handler(trainer, Events.EPOCH_COMPLETED, optimizer=optimizer, param_name='lr')
trainer.add_event_handler(Events.EPOCH_COMPLETED, on_epoch_end)
# 训练数据
train_data = load_from_disk('temp/train_data')['text']
data_param = {'shuffle': True, 'batch_size': batch_size, 'collate_fn': collate_handler}
train_data = DataLoader(train_data, **data_param)
# 调节器
milestones_values = [(0, 5e-5), (math.ceil(num_epoch * len(train_data)), 0)]
scheduler = PiecewiseLinear(optimizer, param_name='lr', milestones_values=milestones_values)
trainer.add_event_handler(Events.ITERATION_STARTED, scheduler)
# 开始训练
trainer.run(train_data, max_epochs=num_epoch)
logger.close()
2. 预测函数
predict_fast 和 predict_slow 是两个预测函数,前者会缓存上文输入的 key 和 value, 预测的速度较快。而后者则是每次输入一个完整上文,重新计算 key、value,随着生成的文本越来越长,其时间耗费也会越来越多,预测非常慢,
import torch
from transformers import GPT2LMHeadModel
from transformers import BertTokenizer
from transformers import GPT2Config
import time
# 设置计算设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def timer(func):
def inner(*args, **kwargs):
print('function [%s] starts execution' % (func.__name__))
start = time.time()
result = func(*args, **kwargs)
end = time.time()
print('function [%s] executed for %.2f seconds' % (func.__name__, end - start))
print('-' * 51)
return result
return inner
@timer
def predict_fast(start_text='李恪', max_len=200):
# 最长 512,按照一整行输出
param = {'add_special_tokens': False, 'return_tensors': 'pt'}
# 对输入内容进行编码
start_encode = tokenizer.encode(start_text, **param)[0]
# 存储预测结果
novel_result = start_encode.tolist()
# 设置初始 past 状态
past_key_values = None
# 预测内容
with torch.no_grad():
for _ in range(max_len):
logits, past_key_values = model(start_encode, past_key_values).values()
y_pred = torch.argmax(logits[-1])
novel_result.append(y_pred.item())
start_encode = y_pred.unsqueeze(0)
# 整理内容
result = tokenizer.decode(novel_result, skip_special_tokens=True)
result = ''.join(result.split())
end_pos = result.rfind('。') + 1
result = result[:end_pos].replace('。', '。\n')
return result
@timer
def predict_slow(start_text='李恪', max_len=200):
param = {'add_special_tokens': False, 'return_tensors': 'pt'}
start_encode = tokenizer.encode(start_text,**param)[0]
novel_result = start_encode.tolist()
# 预测内容
with torch.no_grad():
for _ in range(max_len):
inputs = torch.tensor(novel_result)
logits, _ = model(inputs).values()
y_pred = torch.argmax(logits[-1], dim=-1)
novel_result.append(y_pred.item())
# 整理内容
result = tokenizer.decode(novel_result, skip_special_tokens=True)
result = ''.join(result.split())
end_pos = result.rfind('。') + 1
result = result[:end_pos].replace('。', '。\n')
return result
if __name__ == '__main__':
model_path = 'temp/test/novel_checkpoint_neg_loss=-0.4148.pt'
objects = torch.load(model_path, map_location=device)
tokenizer = BertTokenizer.from_pretrained('model')
config = GPT2Config(vocab_size=tokenizer.vocab_size)
model = GPT2LMHeadModel(config=config)
model.load_state_dict(objects['model'])
model.eval()
result = predict_fast()
print(result)
result = predict_slow()
print(result)
预测结果:
function [predict_fast] starts execution function [predict_fast] executed for 5.01 seconds --------------------------------------------------- 李恪心腹,又受李恪举荐为三军先锋,然三军先锋事关重大,绝不会因为李恪的一纸书信便将大军的先锋官许给眼下还籍籍无名的苏定方,这对于苏定方而言,也是一场考较。 这一场考较若是苏定方过了,有李恪的面子在,先锋官自然就是他的了,可若是此次考较苏定方未能叫李靖满意,以李靖严谨的性子,就算有李恪的手书在,苏定方最多也只能做些闲职。 function [predict_slow] starts execution function [predict_slow] executed for 13.35 seconds --------------------------------------------------- 李恪心腹,又受李恪举荐为三军先锋,然三军先锋事关重大,绝不会因为李恪的一纸书信便将大军的先锋官许给眼下还籍籍无名的苏定方,这对于苏定方而言,也是一场考较。 这一场考较若是苏定方过了,有李恪的面子在,先锋官自然就是他的了,可若是此次考较苏定方未能叫李靖满意,以李靖严谨的性子,就算有李恪的手书在,苏定方最多也只能做些闲职。
 冀公网安备13050302001966号
冀公网安备13050302001966号