


对联是中国传统文化中的一项独特艺术形式,它不仅要求上下句字数相同,还要对仗工整、意义相对。随着人工智能和自然语言处理技术的进步,如何让机器自动生成符合对联规律的文本,变得越来越有趣也越来越可行。接下来,我们将一起探讨如何搭建一个 Seq2Seq + Attention 架构的模型,自动根据输入的上联生成对仗工整的下联。
网络中的编码器和解码器部分我们选择使用 GRU 模型,GRU 是一种比传统 RNN 更加高效的递归神经网络结构,能够有效解决长序列中的梯度消失问题。结合 Seq2Seq 架构,模型可以将输入的序列转换成输出序列,从而生成流畅连贯的文本。再加上 Attention 机制,让模型在生成文本时,能聚焦于输入中最重要的部分,从而提高生成文本的质量和准确性。
接下来,我们会从数据准备、模型搭建、训练生成,逐步实现每个环节。
1. 数据处理
我从互联网搜索到一个包含 70+ 万对联数据的语料,后面的模型训练也是基于该语料进行训练。下面,我们先对数据做一下处理,主要是去重和构建词表。
import pickle
import re
from tqdm import tqdm
# 对联去重
def demo01():
is_unicode = lambda text: any('\ue000' <= char <= '\uf8ff' for char in text)
couplets, hash_set = [], set()
def append(one, two):
one, two = one.strip(), two.strip()
if is_unicode(one) or is_unicode(two):
return
one_hash, two_hash = hash(one), hash(two)
if one_hash not in hash_set and two_hash not in hash_set:
couplets.append((one, two))
hash_set.add(one_hash)
hash_set.add(two_hash)
fnames = (('couplet/train/in.txt', 'couplet/train/out.txt'), ('couplet/test/in.txt', 'couplet/test/out.txt'))
for one_fname, two_fname in fnames:
for one, two in zip(open(one_fname), open(two_fname)):
append(one, two)
# 对联数量: 563114
print('对联数量:', len(couplets))
pickle.dump(couplets[:-5], open('data/couplet-train.pkl', 'wb'))
# [('日 里 千 人 拱 手 划 船 , 齐 歌 狂 吼 川 江 号 子', '夜 间 百 舸 点 灯 敬 佛 , 漫 饮 轻 吟 巴 岳 清 音'),
# ('入 迷 途 , 吞 苦 果 , 回 头 是 岸', '到 此 处 , 改 前 非 , 革 面 做 人'),
# ('地 近 秦 淮 , 看 碧 水 蓝 天 , 一 行 白 鹭 飞 来 何 处', '门 临 闹 市 , 入 红 楼 翠 馆 , 四 海 旅 人 宾 至 如 归'),
# ('其 巧 在 古 倕 以 上', '所 居 介 帝 君 之 间'),
# ('万 众 齐 心 , 已 膺 全 国 文 明 市', '千 帆 竞 发 , 再 鼓 鹭 江 经 济 潮')]
print(couplets[-5:])
def demo02():
index_to_word, word_to_index = {}, {}
couplets = pickle.load(open('data/couplet-train.pkl', 'rb'))
words = set()
for one, two in couplets:
words.update(one.split())
words.update(two.split())
word_to_index = {'[PAD]': 0, '[BEG]': 1, '[END]': 2, '[UNK]': 3}
index_to_word = {0: '[PAD]', 1: '[BEG]', 2: '[END]', 3: '[UNK]'}
for idx, word in enumerate(words, start=len(word_to_index)):
if word not in word_to_index:
word_to_index[word] = idx
index_to_word[idx] = word
# 词表大小: 8794
print('词表大小:', len(word_to_index))
pickle.dump(word_to_index, open('data/word_to_index.pkl', 'wb'))
pickle.dump(index_to_word, open('data/index_to_word.pkl', 'wb'))
if __name__ == '__main__':
demo01()
demo02()
2. 分词器
import pickle
import torch
from torch.nn.utils.rnn import pad_sequence
class Tokenzier:
def __init__(self):
self.word_to_index = pickle.load(open('data/word_to_index.pkl', 'rb'))
self.index_to_word = pickle.load(open('data/index_to_word.pkl', 'rb'))
self.unk = self.word_to_index['[UNK]']
self.pad = self.word_to_index['[PAD]']
def get_vocab_size(self):
return len(self.word_to_index)
def encode(self, texts):
batch_ids, batch_len = [], []
for text in texts:
ids = []
for word in text.split():
if word in self.word_to_index:
index = self.word_to_index[word]
else:
index = self.unk
ids.append(index)
batch_ids.append(torch.tensor(ids))
batch_len.append(len(ids))
# 将批次数据 PAD 对齐
batch_ids = pad_sequence(batch_ids, batch_first=True, padding_value=self.pad)
batch_len = torch.tensor(batch_len)
# 降序排列
indices = torch.argsort(batch_len, descending=True)
batch_ids = batch_ids[indices]
batch_len = batch_len[indices]
return batch_ids, batch_len
def decode(self, token_ids):
content = ''
for token_id in token_ids:
content += self.index_to_word[token_id]
return content
if __name__ == '__main__':
tokenizer = Tokenzier()
ones = ['晚 风 摇 树 树 还 挺', '愿 景 天 成 无 墨 迹 墨 迹']
twos = ['[BEG] 晨 露 润 花 花 更 红 [END]', '[BEG] 万 方 乐 奏 有 于 阗 [END]']
batch_ids, batch_len = tokenizer.encode(ones)
print(batch_ids)
batch_ids, batch_len = tokenizer.encode(twos)
print(batch_ids)
3. 模型搭建
import torch.nn as nn
import torch
from torch.nn.utils.rnn import pad_sequence
from torch.nn.utils.rnn import pack_padded_sequence
from torch.nn.utils.rnn import pad_packed_sequence
class CoupletGenerator(nn.Module):
def __init__(self, vocab_size):
super(CoupletGenerator, self).__init__()
embedd_size, hidden_size = 128, 256
self.vectors = nn.Embedding(num_embeddings=vocab_size, embedding_dim=embedd_size)
self.encoder = nn.GRU(input_size=embedd_size, hidden_size=hidden_size, batch_first=True)
self.decoder = nn.GRU(input_size=embedd_size, hidden_size=hidden_size, batch_first=True)
self.attention = nn.MultiheadAttention(embed_dim=hidden_size, num_heads=1, batch_first=True)
self.outputs = nn.Linear(in_features=hidden_size, out_features=vocab_size)
def generate(self, upper_line, max_length=20, beg_token_id=1, eos_token_id=2):
"""对联生成函数"""
device = next(self.parameters()).device
upper_line = upper_line.to(device)
upper_embed = self.vectors(upper_line)
upper_token_vectors, upper_last_hidden = self.encoder(upper_embed)
start_token = torch.tensor([[beg_token_id]], device=device)
start_embed = self.vectors(start_token)
hx = upper_last_hidden
lower_tokens = []
for _ in range(max_length):
# 编码器理解上联
lower_token_vector, hx = self.decoder(start_embed, hx)
# 进行注意力计算
lower_attention_infos, _ = self.attention(query=lower_token_vector,
key=upper_token_vectors,
value=upper_token_vectors)
lower_token_vector + lower_attention_infos
# 预测当前的标记
lower_logits = self.outputs(lower_token_vector)
lower_next_token = torch.argmax(lower_logits, dim=-1)
lower_tokens.append(lower_next_token.item())
# 输出 [END],则停止生成
if lower_next_token.item() == eos_token_id:
break
start_embed = self.vectors(lower_next_token)
return lower_tokens
def encoder_understand(self, upper_lines, upper_lens):
"""编码器理解上联"""
upper_embed = self.vectors(upper_lines)
upper_embed_packed = pack_padded_sequence(upper_embed, lengths=upper_lens, batch_first=True, enforce_sorted=False)
upper_token_vectors, upper_last_hidden = self.encoder(upper_embed_packed)
upper_token_vectors, upper_lens = pad_packed_sequence(upper_token_vectors, batch_first=True)
return upper_token_vectors, upper_last_hidden
def decoder_generation(self, lower_lines, lower_lens, upper_last_hidden):
"""解码器生成下联"""
lower_embed = self.vectors(lower_lines)
lower_embed_packed = pack_padded_sequence(lower_embed, lengths=lower_lens, batch_first=True, enforce_sorted=False)
lower_token_vectors, lower_last_hidden = self.decoder(lower_embed_packed, upper_last_hidden)
lower_token_vectors, lower_lens = pad_packed_sequence(lower_token_vectors, batch_first=True)
return lower_token_vectors
def forward(self, upper_lines, upper_lens, lower_lines, lower_lens, ignore_index=0):
"""前向计算函数"""
device = next(self.parameters()).device
# 输入数据移动到模型所在设备上
upper_lines, lower_lines = upper_lines.to(device), lower_lines.to(device)
# 编码器对上联理解
upper_token_vectors, upper_last_hidden = self.encoder_understand(upper_lines, upper_lens)
# 解码器生成下联
decoder_labels = lower_lines[:, 1:]
decoder_inputs = lower_lines[:, :-1]
lower_token_vectors = self.decoder_generation(decoder_inputs, lower_lens - 1, upper_last_hidden)
# 上联是一个批次,创建 mask,避免 PAD 参与注意力计算(True 掩码,表示不参与,False 不掩码,表示参与计算)
key_padding_mask = (upper_lines == 0)
lower_attention_vectors, weights = self.attention(query=lower_token_vectors,
key=upper_token_vectors,
value=upper_token_vectors,
key_padding_mask=key_padding_mask)
# 生成 token 时,结合输入 token 的信息
lower_token_vectors += lower_attention_vectors
logits = self.outputs(lower_token_vectors)
# 计算交叉熵损失,标记为 ignore_index 的 token 不计算损失
criterion = nn.CrossEntropyLoss(ignore_index=ignore_index)
lower_loss = criterion(logits.view(-1, self.vectors.num_embeddings), decoder_labels.reshape(-1))
return logits, lower_loss
if __name__ == '__main__':
from tokenizer import Tokenzier
tokenizer = Tokenzier()
upper_lines = ['晚 风 摇 树 树 还 挺', '愿 景 天 成 无 墨 迹 墨 迹']
lower_lines = ['[BEG] 晨 露 润 花 花 更 红 [END]', '[BEG] 万 方 乐 奏 有 于 阗 [END]']
upper_lines, upper_lens = tokenizer.encode(upper_lines)
lower_lines, lower_lens = tokenizer.encode(lower_lines)
estimator = CoupletGenerator(vocab_size=tokenizer.get_vocab_size())
logits, loss = estimator(upper_lines, upper_lens, lower_lines, lower_lens)
upper_lines, upper_lens = tokenizer.encode(['晚 风 摇 树 树 还 挺', ])
text_tokens = estimator.generate(upper_lines)
print(text_tokens)
text = tokenizer.decode(text_tokens)
print(text)
4. 模型训练
from tokenizer import Tokenzier
from torch.utils.data import DataLoader
import pickle
from tqdm import tqdm
from couplet_generator import CoupletGenerator
from tokenizer import Tokenzier
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import torch.optim as optim
from torch.optim.lr_scheduler import StepLR
def train(epochs=10, device='cuda' if torch.cuda.is_available() else 'cpu'):
tokenizer = Tokenzier()
estimator = CoupletGenerator(vocab_size=tokenizer.get_vocab_size()).to(device)
optimizer = optim.Adam(estimator.parameters(), lr=1e-3)
scheduler = StepLR(optimizer, step_size=5000, gamma=0.9)
train_data = pickle.load(open('data/couplet-train.pkl', 'rb'))
def collate_fn(batch_data):
upper_lines, lower_lines = [], []
for upper_line, lower_line in batch_data:
upper_lines.append(upper_line)
lower_lines.append('[BEG] ' + lower_line + ' [END]')
upper_lines, upper_lens = tokenizer.encode(upper_lines)
lower_lines, lower_lens = tokenizer.encode(lower_lines)
return upper_lines, upper_lens, lower_lines, lower_lens
dataloader = DataLoader(train_data, batch_size=64, shuffle=True, collate_fn=collate_fn)
record_loss = []
for epoch in range(epochs):
estimator.train()
total_loss, total_size = 0, 0
progress = tqdm(range(len(dataloader)), ncols=100)
for upper_lines, upper_lens, lower_lines, lower_lens in dataloader:
# 移动输入数据到设备上
upper_lines, lower_lines = upper_lines.to(device), lower_lines.to(device)
# 梯度清零
optimizer.zero_grad()
# 损失计算
logits, loss = estimator(upper_lines, upper_lens, lower_lines, lower_lens)
# 梯度计算
loss.backward()
# 参数更新
optimizer.step()
# 学习率更新
scheduler.step()
# 损失统计
total_loss += loss.item() * torch.sum(lower_lens - 1)
total_size += torch.sum(lower_lens - 1)
progress.set_description(f'Epoch {epoch + 1}/{epochs}, Loss: {total_loss / total_size:.4f} Lr: {scheduler.get_last_lr()[0]:.6f}')
progress.update()
progress.close()
record_loss.append(total_loss / total_size)
# 存储模型
pickle.dump(estimator, open(f'model/couplet-estimator-{epoch + 1}.pkl', 'wb'))
pickle.dump(tokenizer, open(f'model/couplet-tokenizer-{epoch + 1}.pkl', 'wb'))
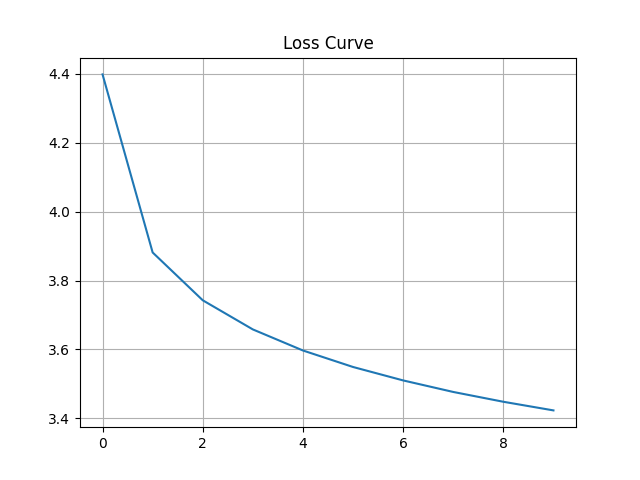
plt.plot(range(len(record_loss)), record_loss)
plt.title('Loss Curve')
plt.grid()
plt.show()
if __name__ == '__main__':
train()
Epoch 1/10, Loss: 4.3985 Lr: 0.001000: 100%|████████████████████| 8799/8799 [01:43<00:00, 85.33it/s] Epoch 2/10, Loss: 3.8814 Lr: 0.000900: 100%|████████████████████| 8799/8799 [01:42<00:00, 85.51it/s] Epoch 3/10, Loss: 3.7426 Lr: 0.000810: 100%|████████████████████| 8799/8799 [01:42<00:00, 85.43it/s] Epoch 4/10, Loss: 3.6580 Lr: 0.000729: 100%|████████████████████| 8799/8799 [01:43<00:00, 85.33it/s] Epoch 5/10, Loss: 3.5968 Lr: 0.000656: 100%|████████████████████| 8799/8799 [01:43<00:00, 85.29it/s] Epoch 6/10, Loss: 3.5489 Lr: 0.000590: 100%|████████████████████| 8799/8799 [01:43<00:00, 85.42it/s] Epoch 7/10, Loss: 3.5099 Lr: 0.000531: 100%|████████████████████| 8799/8799 [01:43<00:00, 85.35it/s] Epoch 8/10, Loss: 3.4764 Lr: 0.000478: 100%|████████████████████| 8799/8799 [01:43<00:00, 85.31it/s] Epoch 9/10, Loss: 3.4479 Lr: 0.000430: 100%|████████████████████| 8799/8799 [01:43<00:00, 85.38it/s] Epoch 10/10, Loss: 3.4228 Lr: 0.000387: 100%|███████████████████| 8799/8799 [01:43<00:00, 85.37it/s]
5. 对联生成
import pickle
import torch
def inference():
estimator = pickle.load(open(f'model/couplet-estimator-7.pkl', 'rb'))
tokenizer = pickle.load(open(f'model/couplet-tokenizer-7.pkl', 'rb'))
upper_lines = [('日 里 千 人 拱 手 划 船 , 齐 歌 狂 吼 川 江 号 子', '夜 间 百 舸 点 灯 敬 佛 , 漫 饮 轻 吟 巴 岳 清 音'),
('入 迷 途 , 吞 苦 果 , 回 头 是 岸', '到 此 处 , 改 前 非 , 革 面 做 人'),
('地 近 秦 淮 , 看 碧 水 蓝 天 , 一 行 白 鹭 飞 来 何 处', '门 临 闹 市 , 入 红 楼 翠 馆 , 四 海 旅 人 宾 至 如 归'),
('其 巧 在 古 倕 以 上', '所 居 介 帝 君 之 间'),
('万 众 齐 心 , 已 膺 全 国 文 明 市', '千 帆 竞 发 , 再 鼓 鹭 江 经 济 潮')]
for upper_line, lower_line in upper_lines:
upper_ids, _ = tokenizer.encode([upper_line])
with torch.no_grad():
generate_lower_line = estimator.generate(upper_ids)
generate_lower_line = tokenizer.decode(generate_lower_line)
print('输入上联:', ''.join(upper_line.split()))
print('参考下联:', ''.join(lower_line.split()))
print('生成下联:', ''.join(generate_lower_line.split()))
print('-' * 50)
if __name__ == '__main__':
inference()
输入上联: 日里千人拱手划船,齐歌狂吼川江号子 参考下联: 夜间百舸点灯敬佛,漫饮轻吟巴岳清音 生成下联: 天中万物归心向日,共建和谐社会文明[END] -------------------------------------------------- 输入上联: 入迷途,吞苦果,回头是岸 参考下联: 到此处,改前非,革面做人 生成下联: 出水水,流光花,出手为天[END] -------------------------------------------------- 输入上联: 地近秦淮,看碧水蓝天,一行白鹭飞来何处 参考下联: 门临闹市,入红楼翠馆,四海旅人宾至如归 生成下联: 天高云汉,听黄河碧浪,千里青山隐去无边[END] -------------------------------------------------- 输入上联: 其巧在古倕以上 参考下联: 所居介帝君之间 生成下联: 斯文于武城而后[END] -------------------------------------------------- 输入上联: 万众齐心,已膺全国文明市 参考下联: 千帆竞发,再鼓鹭江经济潮 生成下联: 千秋大业,再绘宏图锦绣图[END] --------------------------------------------------
 冀公网安备13050302001966号
冀公网安备13050302001966号