


值类别是 C++11 为适配移动语义而引入的重要概念,要理解这个概念我们得了解:左值、右值、将亡值、纯右值的概念,以及引入这些概念的原因。
1. 左值右值
在 C++ 中,表达式指的是任何可以被求值(evaluated)并产生一个结果(value)的语法结构,每个表达式都有两个非常重要的属性:它的类型是什么?它是左值还是右值?
- 类型是反映的是该表达式在执行后所产生的值的类型
- 左值表示具有身份(identity)的对象(可取地址),右值表示无身份的纯值(不可取地址)
int x = 10;
int y = 20;
int arr[3] = { 1, 2, 3 };
// 返回普通值 → 右值
int f() { return 42; }
// 返回引用 → 左值
int& g() { return x; }
struct S
{
int m;
S(int v) : m(v) {}
int get() { return m; } // 返回副本 → 右值
int& ref() { return m; } // 返回引用 → 左值
};
S makeS() { return S(99); } // 返回临时对象 → 右值
int main()
{
// ———————— 字面量 ————————
42; // int, rvalue
3.14; // double, rvalue
'a'; // char, rvalue
"hello"; // const char[6], lvalue(字符串字面量是例外,保留说明)
// ———————— 变量 ————————
x; // int, lvalue
// ———————— 函数调用 ————————
f(); // int, rvalue
g(); // int, lvalue
// ———————— 自增/自减 ————————
x++; // int, rvalue(返回旧值副本)
++x; // int, lvalue(返回自身引用)
// ———————— 赋值类表达式 ————————
(x = 5); // int, lvalue
(x += 3); // int, lvalue
// ———————— 条件运算符 ?: ————————
(x > 0 ? x : y); // int, lvalue(两分支均为左值)
(x > 0 ? x : 42); // int, rvalue(混合左值/右值 → 整体为右值)
// ———————— 数组与指针 ————————
arr[1]; // int, lvalue
int* p = &x;
*p; // int, lvalue
// ———————— 成员访问 ————————
S s(100);
s.m; // int, lvalue
s.get(); // int, rvalue
s.ref(); // int, lvalue
S* ps = &s;
ps->m; // int, lvalue
// ———————— 临时对象 ————————
S(200); // S, rvalue
return 0;
}
在 C++11 之前,左值 vs 右值 的核心作用是确保操作符合法性,从而支撑语言的基本规则:例如,赋值运算符的左操作数必须是左值,取地址操作仅适用于左值。
int a = 10; // 报错 "=": 左操作数必须为左值 (a + 5) = 10; // 报错 非常量引用的初始值必须为左值 int& r = 10;
2. 拷贝优化
随着程序复杂度的提升,代码中涉及的对象数量显著增加,大量对象拷贝操作会引入不可忽视的时间与空间开销。其中,右值中的临时对象,正是这类冗余开销的核心来源之一。
从本质来看,右值表达式的核心特征是运行时临时生成、无显式名称、生命周期严格局限于当前表达式。其求值完成后会立即销毁,后续不会被任何代码访问或复用。这意味着,针对右值临时对象的拷贝操作完全冗余:相当于复制了一份即将被销毁的资源,既浪费了拷贝开销,也未带来任何实际价值。
针对临时对象拷贝冗余的问题,GCC、Clang、MSVC 等主流编译器早已提供优化方案:在严格保证程序可观测行为不变的前提下,通过直接在目标对象的内存位置构造临时对象,避免对临时对象的拷贝。
但这类优化存在明显局限:一方面在复杂场景(如条件分支嵌套、多态对象返回)中易失效,无法覆盖所有临时对象的应用场景;另一方面,对于需要避免拷贝的左值对象(如已命名的长期存活对象),这类编译器优化几乎完全不起作用。
#include <iostream>
#include <vector>
struct MyClass
{
MyClass(int num)
{
m_num = num;
p_data = new int[m_num];
for (int i = 0; i < m_num; ++i)
{
p_data[i] = i;
}
std::cout << "构造函数" << std::endl;
}
MyClass(const MyClass& other)
{
m_num = other.m_num;
p_data = new int[m_num];
for (int i = 0; i < m_num; ++i)
{
p_data[i] = other.p_data[i];
}
std::cout << "拷贝构造" << std::endl;
}
~MyClass()
{
if (p_data != nullptr)
{
delete[] p_data;
p_data = nullptr;
}
std::cout << "析构函数" << std::endl;
}
int* p_data;
int m_num;
};
void func(MyClass mc)
{
(void)mc;
}
MyClass demo()
{
MyClass mc(10);
return mc;
}
void test01()
{
// Demo(10) 直接在 demo01 的参数位置构造,避免对象拷贝。
func(MyClass(10));
// demo02 中的局部对象 d 直接在 test 中变量 demo 的内存位置构造,避免对象拷贝。
MyClass mc = demo();
std::cout << &demo << std::endl;
}
// 2. 优化不生效场景
MyClass create_myclass(bool flag)
{
MyClass mc1(10);
MyClass mc2(20);
if (flag)
{
return mc1;
}
else
{
return mc2;
}
}
void test02()
{
// 1. 右值场景
// 临时对象无法优化,仍需要进行拷贝
std::vector<MyClass> vec;
vec.push_back(MyClass(10));
std::cout << "-----------" << std::endl;
MyClass ret = create_myclass(true);
std::cout << "-----------" << std::endl;
// 2. 左值场景
MyClass mc1(100);
func(mc1);
std::cout << "-----------" << std::endl;
MyClass mc2(100);
std::vector<MyClass> vec2;
vec2.push_back(mc2);
std::cout << "-----------" << std::endl;
}
int main()
{
// test01();
test02();
return 0;
}
3. 移动语义
由于编译器优化的局限性,C++11 正式引入移动语义,为右值与左值的拷贝场景提供了更精准、更通用的优化方案。其核心思想:当一个对象处于 “即将销毁” 或 “不再需要” 的状态时,不再进行耗时的深拷贝,而是允许新对象直接接管其内部资源,消除拷贝开销。
对于右值而言,其 “转瞬即逝、用完即销毁” 的特性恰好与移动语义的适用场景完美契合,相当于 “我马上要被销毁,无需拷贝,直接取走我的资源即可” ,因此移动语义能在右值对象上天然生效。
而左值作为有显式名称、可能在后续代码中继续被访问的对象,若贸然转移其资源,会导致原对象被 “掏空”,进而引发访问非法内存等语义错误,因此语言默认不会对左值触发移动语义。
但实际开发中,我们常会遇到 “某个左值后续确实不再使用” 的场景。可通过 std::move 显式将左值标记为 “可移动” 的右值引用类型,从而安全触发移动语义。std::move 不会改变对象的左值属性,被标记的对象依然是左值,它只是告知编译器你可以把我当右值对待。
需要特别注意的是:一旦左值对象被移动后,其内部状态会变得不确定,后续不应再对其进行访问或操作。
#include <iostream>
#include <vector>
struct MyClass
{
MyClass(int num)
{
m_num = num;
p_data = new int[m_num];
for (int i = 0; i < m_num; ++i)
{
p_data[i] = i;
}
std::cout << "构造函数" << std::endl;
}
MyClass(const MyClass& other)
{
m_num = other.m_num;
p_data = new int[m_num];
for (int i = 0; i < m_num; ++i)
{
p_data[i] = other.p_data[i];
}
std::cout << "拷贝构造" << std::endl;
}
// --------移动构造------------
MyClass(MyClass&& other) noexcept
{
m_num = other.m_num;
p_data = other.p_data;
other.m_num = 0;
other.p_data = nullptr;
std::cout << "移动构造" << std::endl;
}
// ---------------------------
~MyClass()
{
if (p_data != nullptr)
{
delete[] p_data;
p_data = nullptr;
}
std::cout << "析构函数" << std::endl;
}
int* p_data;
int m_num;
};
void func(MyClass mc)
{
(void)mc;
}
MyClass demo(bool flag)
{
MyClass mc1(10);
MyClass mc2(20);
if (flag)
{
return mc1;
}
else
{
return mc2;
}
}
void test()
{
// 1. 右值场景
std::vector<MyClass> vec;
vec.push_back(MyClass(10));
std::cout << "-----------" << std::endl;
MyClass ret = demo(true);
std::cout << "-----------" << std::endl;
// 2. 左值场景
MyClass mc1(100);
func(std::move(mc1));
std::cout << "-----------" << std::endl;
MyClass mc2(100);
std::vector<MyClass> vec2;
vec2.push_back(std::move(mc2));
std::cout << "-----------" << std::endl;
}
int main()
{
test();
return 0;
}
通过移动语义,我们可以进一步降低拷贝开销、提升程序性能。与此同时,值类别的体系也随之发生变化:
广义左值(glvalue)
- 左值(lvalue):对应 C++11 之前的传统左值,可标记、不可移动
- 将亡值(xvalue):被标记为
T&&的左值对象,可标记、可移动
广义右值(rvalue)
- 纯右值(prvalue):对应 C++11 之前的传统右值(如临时对象、字面量等),不可标记、可移动
- 将亡值(xvalue):被标记为
T&&的左值对象,属于特殊的右值,可标记、可移动
我们可以根据 “可标记性”“可移动性”,将表达式的值类别体系归纳为如下结构:
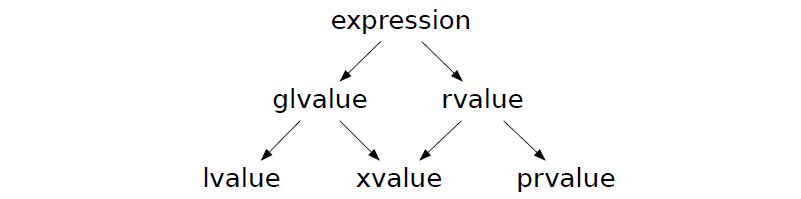
最后,我们简单总结下, C++98/03 二分法:左值、右值(主要关注是否具有身份), C++11 的三分法:左值、纯右值、将亡值(同时关注是否具有身份、是否可以移动)。

 冀公网安备13050302001966号
冀公网安备13050302001966号