


TF-IDF(Term Frequency – Inverse Document Frequency)是一种用于信息检索与文本挖掘的常用技术。
通过 TF-IDF 我们可以实现:
- 评估文档中每个词的重要性,实现对文档的关键词抽取
- 将输入文档表示为向量(关键词重要性向量),可用于文档检索
1. 算法公式
TF-IDF 可以评估文档中某个词的重要性,其计算公式:TF-IDF = TF * IDF。通过该公式,我们得知,评估一个词的重要性时,该算法要综合考虑该词的 TF 值和 IDF 值。
- TF: 表示某个词在文档中出现的次数。如果该词在文档中出现的次数越多,TF 值就越大。
- IDF:表示包含某个词的文档数量。如果包含该词的文档数量越少,IDF 值就越大。
例如:词 A 和 词 B 是某个文档中出现的词,两个词在文档中出现的次数一样多,但是:
- 同时,词 A 在其他文档中大量出现。
- 同时,词 B 在其他文档中很少出现。
TF-IDF 认为:词 A 在其他文档中大量出现,说明该词很普遍,会降低该词的重要性。反之,则认为该词更为重要。
1.1 TF(词频)

采用对数平滑的方式有助于减小高频词对文档的影响,避免某些词对文档特征表示的过度影响。
import numpy as np
if __name__ == '__main__':
tf = np.array([20, 5, 2])
print(tf)
tf = np.log(tf)
print(tf)
输出结果:
[20 5 2] [2.99573227 1.60943791 0.69314718]
1.2 IDF(逆文档词频)

IDF平滑的作用是什么?
IDF 的平滑计算目的是为了避免分母为 0,默认情况下,在计算时,都会默认进行 IDF 平滑。
关于分母为0情况的补充说明:
正常根据语料计算每个词的 TF 和 IDF 时,IDF 一般不需要平滑,因为不太可能出现 IDF 分母为 0 的情况。但是,在具体实现 TFIDF 算法时,比如在 scikit-learn 中的实现,它是允许我们传入自己的词表的,而不是根据训练语料构建词表。此时,词表中的有些词就可能在语料中不存在,使得出现分母为 0 的情况。此时,使用平滑之后就能够解决这个实际应用中的问题。下面为示例代码:
from sklearn.feature_extraction.text import TfidfVectorizer
def test():
# 训练语料
texts = ['我们 是 中国人 中国人', '中国人 很 很 厉害', '他们 真的 厉害 吗 ?']
# 自定义词表
vocabulary = ['中国人', '他们', '厉害', '我们', '真的', '大地']
# 我们手动设置对 IDF 不平滑,即:smooth_idf=False
tfidf = TfidfVectorizer(smooth_idf=False, vocabulary=vocabulary)
# 因为 "大地" 这个自定义词表中的词在训练语料中不存在,则报错如下:
# 报错:RuntimeWarning: divide by zero encountered in divide self.idf_ = np.log(n_samples / df) + 1.0
tfidf.fit(texts)
print(tfidf.get_feature_names_out())
print(tfidf.idf_)
if __name__ == '__main__':
test()
公式能够反映出的信息是什么?
文档集合中,包含某个词的文档数量越多,该词的 IDF 值就越小。反之,则越大。
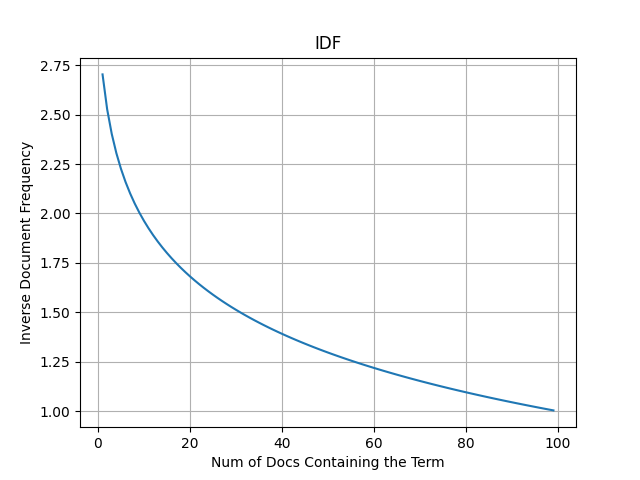
import matplotlib.pyplot as plt
import numpy as np
def test():
doc_num = 100
x = np.arange(1, 100)
y = np.log((doc_num + 1) / (x + 1)) + 1
plt.plot(x, y)
plt.xlabel('Num of Docs Containing the Term')
plt.ylabel('Inverse Document Frequency')
plt.grid(True)
plt.show()
if __name__ == '__main__':
test()
为什么进行 log 计算?
对数函数能够将大范围的值映射到相对较小的范围内。这对于在不同文档中频率差异较大的词语来说尤其重要。通过取对数,可以有效地缩小高频词的影响,使得低频词在计算中更具影响力。
比如:共有 10000 个文档,某个词出现次数为 2,和出现次数为 1000,值分别为 5000 和 10,这个数值差距会很大。通过取对数值变为 [8.5 2.3],使得词影响均衡一些。
2. 算法使用
在这一节中,主要给同学们讲解下 TF-IDF 算法 API 的使用方法(scikit-learn 库),以及该 API 是如何将输入的文档转换为 TF-IDF 向量。
scikit-learn(sklearn)是一个用于机器学习的 Python 库,常用于数据挖掘和数据分析。它包含了各种机器学习算法和工具,支持分类、回归、聚类等任务,以及类似 TF-IDF 的特征提取算法。
pip install scikit-learn
2.1 API 使用
在 scikit-learn 中实现 TF-IDF 算法。下面我们将学习其使用方法:
from sklearn.feature_extraction.text import TfidfVectorizer
# 注意: 文档需要先进行分词,以空格隔开
texts = ['我们 是 中国人 中国人', '中国人 很 很 厉害', '他们 真的 厉害 吗 ?']
def test():
tfidf = TfidfVectorizer()
result = tfidf.fit_transform(texts)
print(tfidf.get_feature_names_out())
print(result.toarray())
if __name__ == '__main__':
test()
程序输出结果:
[[0.83559154 0. 0. 0.54935123 0. ] [0.70710678 0. 0.70710678 0. 0. ] [0. 0.62276601 0.4736296 0. 0.62276601]]
2.2 API 工作
TfidfVectorizer 的计算过程如下:
- 首先,根据输入的多个文档、预料构建词表
- 然后,统计每篇文档中,词表中的词出现的次数
- 接着,计算每个词的平滑之后的 TF-IDF 值
- 最后,对每个文档 TF-IDF 向量进行 L2 标准化
1. TFIDF 会根据空格将输入文档切分成词列表,并去除单字词、标点符号 ['中国人' '他们' '厉害' '我们' '真的'] 2. 统计每个文档中,词表中的词出现次数 [[2 0 0 1 0] [1 0 1 0 0] [0 1 1 0 1]] 3. 计算每个词平滑之后的 TF-IDF 值 [[2.57536414 0. 0. 1.69314718 0. ] [1.28768207 0. 1.28768207 0. 0. ] [0. 1.69314718 1.28768207 0. 1.69314718]] 4. 计算每个向量 L2 标准化之后的值 [[0.83559154 0. 0. 0.54935123 0. ] [0.70710678 0. 0.70710678 0. 0. ] [0. 0.62276601 0.4736296 0. 0.62276601]]
3. 参数详解
TfidfVectorizer 实现中,包含了很多相关参数,接下来,将会详细讲解其中的大多数参数的作用。
3.1 文档处理相关参数
# 指定文档预处理函数 preprocessor=None # 指定分词是词粒度(word)还是字符粒度(char) analyzer='word' # 文本内容是否小写 lowercase=True
3.2 词表构建相关参数
# 用于切分出词的规则 token_pattern=r"(?u)\b\w\w+\b" # 增加 N-Gram 特征词 ngram_range=(1, 1) # 将某个词在整个文档列表中出现次数大于 max_df 的词从词表中去除 max_df=1.0 # 将某个词在整个文档列表中出现次数小于 max_df 的词从词表中去除 min_df=1 # 将 TF 值最大的前 Top N 保留 max_features=None # 指定自定义词表 vocabulary=None # 去除停用词 stop_words=None
3.3 影响计算相关参数
# 指定是否对 TF-IDF 向量进行标准化, 值可选:l1、l2 norm='l2' # 是否计算 idf 值,如果为 False, idf(t) = 1. use_idf=True # 是否进行 TF-IDF 平滑计算 smooth_idf=True # sublinear_tf 的设置影响 TF 的计算方式 sublinear_tf=False


 冀公网安备13050302001966号
冀公网安备13050302001966号
nb