


MediaPipe 是 Google 开源的跨平台、可定制化机器学习解决方案框架,专注于快速构建和部署实时多媒体(图像、视频、音频)处理应用,尤其在人体视觉分析任务(人脸识别、姿态检测、手势识别等)上表现优异。其核心优势是将复杂的 ML 模型封装为独立可调用的组件,无需从零训练模型,开箱即用即可实现各类视觉功能,极大降低了 AI 应用的开发门槛。
本文将从环境准备、手部关键点检测、官方预设手势识别、自定义手势训练与识别四个核心部分,手把手教你掌握 MediaPipe 手势识别的全流程使用,所有示例代码均可直接运行。
MediaPipe GitHub 仓库:https://github.com/google-ai-edge/mediapipe
MediaPipe 中文文档:https://ai.google.dev/edge/mediapipe/solutions/setup_python?hl=zh-cn
# 安装 MediaPipe 核心库(支持手势检测、关键点提取) pip install mediapipe # 安装 opencv(用于视频/摄像头处理) pip install opencv-python # 自定义手势训练 pip install mediapipe-model-maker
MediaPipe 的手势相关功能依赖预训练的模型文件:
hand_landmarker.task:手部关键点检测核心模型,用于检测手部区域并提取 21 个关键点gesture_recognizer.task:官方预设手势识别模型,基于 21 个关键点实现 8 种常见手势分类
1. 关键点检测
手部关键点检测是手势识别的基础,MediaPipe 通过 hand_landmarker.task 模型实现,该模型内部包含两个子模型,形成完整的检测流水线:
- palm_detection_full.tflite 用于检测图像中是否存在手,并定位手部区域。
- hand_landmark_full.tflite 在该区域内提取 21 个手部关键点(手腕与各手指关节),并判断左右手。
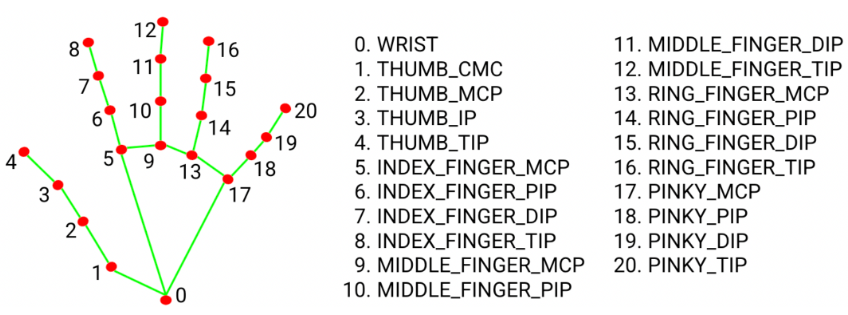
21 个关键点:按固定索引编号,覆盖手腕(0 号)、拇指(1-4)、食指(5-8)、中指(9-12)、无名指(13-16)、小指(17-20)。每一个关键点是一个三维坐标(x, y, z),表示关键点在图像的位置信息,它是归一化后坐标,[0,1] 区间的值,需乘以图像实际宽高转换为实际图像坐标才能可视化。
1.1 模型加载
hand_landmarker.task 的推理过程主要包含三个核心阶段:检测(Detection)、验证(Presence Validation)和关键点定位(Landmark Localization),并在视频或实时流模式下通过跟踪(Tracking)机制进一步提升效率。
在检测阶段,模型首先对输入图像进行全局扫描,生成一系列可能包含手的候选区域,并为每个候选区域计算检测置信度,去掉低于 min_hand_detection_confidence 的候选区域。随后,去除高度重叠的候选框,并根据置信度进行排序,最终保留最多 num_hands 个候选区域进入下一阶段。
进入验证阶段后,模型会对每个候选区域进行更精细的判断,评估该区域内是否真实存在手部结构,并输出对应的存在性置信度。若某候选区域的存在性置信度低于 min_hand_presence_confidence,则会被剔除,不再继续处理。
通过验证的手部区域将进入关键点定位阶段,模型在该阶段中预测手部 21 个关键点的精确坐标,从而完成一次完整的推理流程。
在 VIDEO 或 LIVE_STREAM 模式下,HandLandmarker 还会启用跟踪机制以优化连续帧的处理效率。模型会利用上一帧的手部位置和特征,预测当前帧中手的可能位置,并给出跟踪置信度。若跟踪置信度高于 min_tracking_confidence,则直接基于跟踪结果进行关键点微调,跳过检测阶段以提升速度;若跟踪置信度低于阈值,则重新执行完整的检测→验证→关键点流程,以确保结果的准确性。
核心工作模式:
- IMAGE 模式用于单张图片处理。每一帧都会从零开始执行完整的手部检测和关键点推理,不使用上一帧信息,也不存在跟踪逻辑,结果稳定但计算开销最大。
- VIDEO 模式用于连续视频帧。系统会优先基于上一帧的结果在当前帧中跟踪手的位置,只有当跟踪不可靠时才重新进行全图检测,因此性能更好、关键点抖动更小,适合实时视频处理。
- LIVE_STREAM 模式用于实时输入流。推理过程是异步的,通过回调返回结果以避免阻塞主线程,其检测与跟踪策略与 VIDEO 模式一致,更适合摄像头等实时场景。
import time
from mediapipe.tasks.python.vision import HandLandmarker
from mediapipe.tasks.python.vision import HandLandmarkerOptions
from mediapipe.tasks.python import BaseOptions
from mediapipe.tasks.python.vision import RunningMode
from mediapipe import Image, ImageFormat
def demo():
# 1. 模型加载
base_options = BaseOptions(model_asset_path='model/already/hand_landmarker.task')
options = HandLandmarkerOptions(base_options=base_options,
running_mode=RunningMode.IMAGE,
num_hands=2,
min_hand_detection_confidence=0.5,
min_hand_presence_confidence=0.5,
min_tracking_confidence=0.5)
detector = HandLandmarker.create_from_options(options=options)
# 2. 模型使用
# 2.1 IMAGE 模式
detector.detect()
# 2.2 VIDEO 模式
detector.detect_for_video()
# 2.3 LIVE_STREAM 模式,需要 options 设置 result_callback(result, timestamp_ms) 回调函数
detector.detect_async()
if __name__ == '__main__':
demo()
1.2 使用示例
from mediapipe.tasks.python.vision import HandLandmarker
from mediapipe.tasks.python.vision import HandLandmarkerOptions
from mediapipe.tasks.python import BaseOptions
from mediapipe.tasks.python.vision import RunningMode
from mediapipe import Image, ImageFormat
import cv2
import time
def get_detector(mode=RunningMode.IMAGE, num_hands=2, result_callback=None):
base_options = BaseOptions(model_asset_path='model/already/hand_landmarker.task')
options = HandLandmarkerOptions(base_options=base_options,
running_mode=mode,
num_hands=num_hands,
result_callback=result_callback)
detector = HandLandmarker.create_from_options(options=options)
return detector
def draw_hand_landmarks(origin, hand_landmarks):
origin_height, origin_width, _ = origin.shape
# 遍历所有手部关键点
for landmark in hand_landmarks:
for idx, pos in enumerate(landmark):
x = int(pos.x * origin_width)
y = int(pos.y * origin_height)
cv2.circle(origin, center=(x, y), radius=3, color=(0, 0, 0), thickness=-1)
cv2.imshow('example', origin)
cv2.waitKey(1)
# 1. IMAGE 模式
def demo01():
# 1. 读取图像
origin = cv2.imread('assets/double.jpeg')
single = cv2.cvtColor(origin, cv2.COLOR_BGR2RGB)
single = Image(image_format=ImageFormat.SRGB, data=single)
# 2. 加载模型
detector = get_detector(mode=RunningMode.IMAGE)
# 3. 关键点检测
result = detector.detect(single)
detector.close()
# print(result.handedness) # 识别左右手
for handedness in result.handedness:
print(f'左右手置信度: {handedness[0].score:.2f} 预测结果:{handedness[0].category_name}')
# print(result.hand_landmarks) # 21 个关键点
draw_hand_landmarks(origin, result.hand_landmarks)
# 2. VEDIO 模式
def demo02():
# 1. 打开视频
cap = cv2.VideoCapture('assets/video.mp4')
fps = int(cap.get(cv2.CAP_PROP_FPS))
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
# 检查视频是否成功打开
if not cap.isOpened():
print('视频打开失败')
return
# 2. 视频检测
detector = get_detector(mode=RunningMode.VIDEO)
while True:
success, origin = cap.read()
if not success:
break
frame = cv2.cvtColor(origin, cv2.COLOR_BGR2RGB)
frame = Image(image_format=ImageFormat.SRGB, data=frame)
timestamp_ms = int(time.time() * 1000)
result = detector.detect_for_video(frame, timestamp_ms=timestamp_ms)
draw_hand_landmarks(origin, result.hand_landmarks)
detector.close()
cap.release()
cv2.destroyAllWindows()
# 2. LIVE_STREAM 模式
def demo03():
# 1. 打开摄像头
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)
cap.set(cv2.CAP_PROP_FPS, 30)
time.sleep(1)
if not cap.isOpened():
return
# 2. 加载模型
detect_result = None
def result_callback(result, output_image, timestamp_ms):
nonlocal detect_result
detect_result = result
detector = get_detector(mode=RunningMode.LIVE_STREAM, result_callback=result_callback)
# 3. 关键点检测
while True:
# 读取视频帧
success, origin = cap.read()
if not success:
break
frame = cv2.cvtColor(origin, cv2.COLOR_BGR2RGB)
frame = Image(image_format=ImageFormat.SRGB, data=frame)
timestamp_ms = int(time.time() * 1000)
detector.detect_async(frame, timestamp_ms=timestamp_ms)
if detect_result is not None:
draw_hand_landmarks(origin, detect_result.hand_landmarks)
detector.close()
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
# demo01()
# demo02()
demo03()
2. 手势识别
基于手部 21 个关键点,MediaPipe 提供了预训练的 gesture_recognizer.task 模型,可直接实现8 种常见手势的分类识别,无需额外训练,该模型是一个完整的流水线模型,由 4 个子模型依次执行:
- 手掌检测:
palm_detection_full.tflite(定位手部区域) - 关键点提取:
hand_landmark_full.tflite(提取 21 个关键点,判断左右手) - 特征生成:
gesture_embedder.tflite(将关键点转换为标准化的手势特征向量) - 手势分类:
canned_gesture_classifier.tflite(将特征向量分类为具体手势)
预测的模型可以识别的手势如下:
| 索引 | 手势名称 | 中文含义 | 索引 | 手势名称 | 中文含义 |
|---|---|---|---|---|---|
| 0 | Unknown | 无法识别的手势 | 4 | Thumb_Down | 向下竖大拇指(差评) |
| 1 | Closed_Fist | 握拳 | 5 | Thumb_Up | 向上竖大拇指(点赞) |
| 2 | Open_Palm | 张开的手掌 | 6 | Victory | 胜利手势(剪刀手) |
| 3 | Pointing_Up | 食指向上 | 7 | ILoveYou | 我爱你手势(摇滚手) |
下面是我给出的使用示例:
from mediapipe.tasks.python.vision import GestureRecognizer
from mediapipe.tasks.python.vision import GestureRecognizerOptions
from mediapipe.tasks.python.vision import RunningMode
from mediapipe.tasks.python.vision import GestureRecognizer
from mediapipe.tasks.python import BaseOptions
from mediapipe.tasks.python.components.processors import ClassifierOptions
from mediapipe import Image
from mediapipe import ImageFormat
import time
import cv2
# 1. 静态手势识别
def demo01():
# score_threshold: 过滤掉分数小于该阈值的预测标签
# category_allowlist: 预测的类别不在这个列表,返回空列表
classifier_option = ClassifierOptions(score_threshold=0.5,
category_allowlist=['None', 'Closed_Fist', 'Open_Palm', 'Pointing_Up', 'Thumb_Down', 'Thumb_Up', 'Victory', 'ILoveYou'])
base_options = BaseOptions(model_asset_path='model/already/gesture_recognizer.task')
options = GestureRecognizerOptions(base_options=base_options,
running_mode=RunningMode.IMAGE,
canned_gesture_classifier_options=classifier_option)
with GestureRecognizer.create_from_options(options) as recognizer:
for image in ['assets/single.jpeg', 'assets/victory.jpg']:
single = Image.create_from_file(image)
output = recognizer.recognize(single)
# 输出是左手还是右手
# print(output.handedness)
# 输出手部关键点信息
# print(len(output.hand_landmarks[0]), output.hand_landmarks)
# landmarks = output.hand_landmarks[0]
# 输出手势的类别
print(output.gestures)
# 2. 实时手势识别
def demo02():
# 打开摄像头
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)
cap.set(cv2.CAP_PROP_FPS, 30)
time.sleep(1)
if not cap.isOpened():
return
base_options = BaseOptions(model_asset_path='model/already/gesture_recognizer.task')
options = GestureRecognizerOptions(base_options=base_options, running_mode=RunningMode.VIDEO)
with GestureRecognizer.create_from_options(options) as recognizer:
while True:
success, origin = cap.read()
if not success:
break
if cv2.waitKey(1) & 0xFF == ord('q'):
break
frame = cv2.cvtColor(origin, cv2.COLOR_BGR2RGB)
frame = Image(image_format=ImageFormat.SRGB, data=frame)
timestamp_ms = int(time.time() * 1000)
result = recognizer.recognize_for_video(frame, timestamp_ms=timestamp_ms)
if result.gestures:
category_name = result.gestures[0][0].category_name
print('手势类别:', category_name)
cv2.imshow('显示图像', origin)
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
# demo01()
demo02()
3. 自定义识别
官方预设手势仅支持 8 种,无法满足个性化需求(如自定义数字手势、操作手势等),MediaPipe 提供了mediapipe-model-maker工具,支持基于自有数据集训练自定义手势识别模型,核心特点:
- 模型兼容:训练后的模型格式与官方模型一致,可直接替换
gesture_recognizer.task使用,调用代码完全不变 - 训练轻量化:仅训练手势识别流水线的最后一层分类模型,前 3 层(检测、关键点提取、特征生成)使用官方预训练模型,无需重新训练,训练速度快、资源占用低
- 数据集简单:仅需采集自定义手势的图片,按类别分文件夹存放即可,无需标注关键点
自定义手势训练三步骤:数据采集 → 模型训练 → 模型使用,数据采集(摄像头录入手势图片),要求如下:
- 数据集目录结构:根目录(如
data)下按手势类别创建子目录,子目录名即为手势类别名称,目录名使用英文,尽量不要包含中文。 - 必须包含
none类别:用于表示无法识别的手势,none 目录下必须包含手部图片,但不是自定义的目标手势(如随意抬手、握拳外的其他手势),否则模型易误检。 - 数据量要求:越多训练效果越好,采集时保证手部在画面中清晰,背景简单,多变换角度 / 距离,提升模型泛化能力。学习时,每个类别采集 20 张左右即可看到训练效果。
data/ ├─ none/ # 非目标手势(必须有) │ ├─ 0.jpg │ ├─ 1.jpg │ └─ ... ├─ gesture_1/ # 自定义手势1:数字1 │ ├─ 0.jpg │ └─ ... ├─ gesture_2/ # 自定义手势2:数字2 │ ├─ 0.jpg │ └─ ... └─ gesture_n/ # 自定义手势3:OK手 ├─ 0.jpg └─ ...
下面是我写的示例代码:
# 1. 数据采集
def demo01():
import time
import cv2
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)
cap.set(cv2.CAP_PROP_FPS, 30)
if not cap.isOpened():
return
save_path = 'data/none'
image_count = 0
print('摄像头启动中...')
time.sleep(1)
while True:
ret, frame = cap.read()
cv2.imshow('frame', frame)
key = cv2.waitKey(1) & 0xFF
if key == 32:
cv2.imwrite(f'{save_path}/{image_count}.jpg', frame)
print(f'已保存图片: {save_path}/{image_count}.jpg')
image_count += 1
if key == ord('q'):
print("程序退出.")
break
cap.release()
cv2.destroyAllWindows()
# 2. 模型训练
def demo02():
from mediapipe_model_maker import gesture_recognizer
from mediapipe_model_maker.python.vision.gesture_recognizer import HandDataPreprocessingParams
from mediapipe_model_maker.python.vision.gesture_recognizer import Dataset
from mediapipe_model_maker.python.vision.gesture_recognizer import HParams
from mediapipe_model_maker.python.vision.gesture_recognizer import GestureRecognizerOptions
from mediapipe_model_maker.python.vision.gesture_recognizer import GestureRecognizer
hparams = HandDataPreprocessingParams(shuffle=True, min_detection_confidence=0.7)
dataset = Dataset.from_folder(dirname='data', hparams=hparams)
print(data.label_names)
print(data.size)
train_data, rest_data = dataset.split(0.8)
# valid_data, test_data = rest_data.split(0.5)
hparams = HParams(export_dir='model/custom', epochs=10, shuffle=True, learning_rate=1e-3)
options = GestureRecognizerOptions(hparams=hparams)
gesture = GestureRecognizer.create(train_data=data, validation_data=rest_data, options=options)
# loss, acc = model.evaluate(test_data, batch_size=1)
# print(f'测试集损失:{loss}, 测试集准确率:{acc}')
gesture.export_model()
# 3. 手势识别
def demo03():
from mediapipe.tasks.python.vision import GestureRecognizer
from mediapipe.tasks.python.vision import GestureRecognizerOptions
from mediapipe.tasks.python.vision import RunningMode
from mediapipe.tasks.python.vision import GestureRecognizer
from mediapipe.tasks.python import BaseOptions
from mediapipe import Image
from mediapipe import ImageFormat
import time
import cv2
# 打开摄像头
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)
cap.set(cv2.CAP_PROP_FPS, 30)
time.sleep(1)
# 检查摄像头是否成功打开
if not cap.isOpened():
return
# 1. 控制手势识别的执行频率
base_options = BaseOptions(model_asset_path='model/custom/gesture_recognizer.task')
options = GestureRecognizerOptions(base_options=base_options, running_mode=RunningMode.VIDEO)
with GestureRecognizer.create_from_options(options) as recognizer:
while True:
success, origin = cap.read()
if not success:
break
cv2.imshow('frame', origin)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
frame = cv2.cvtColor(origin, cv2.COLOR_BGR2RGB)
frame = Image(image_format=ImageFormat.SRGB, data=frame)
timestamp_ms = int(time.time() * 1000)
result = recognizer.recognize_for_video(frame, timestamp_ms=timestamp_ms)
if result.gestures:
category_name = result.gestures[0][0].category_name
print('手势类别:', category_name)
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
# demo01()
# demo02()
demo03()
 冀公网安备13050302001966号
冀公网安备13050302001966号