
GBDT(Gradient Boosting Decision Tree,梯度提升树)是由 Friedman 提出的一种经典的集成学习算法。它以高精度和强鲁棒性著称,能在回归与分类等多种任务中表现出色。正因其灵活而高效的特性,GBDT 也成为后续诸多算法(如 XGBoost、LightGBM)的理论基础与灵感来源。
在本课程中,我们将从直观入手,带你用 GBDT 实现分类与回归任务,理解其基本思想与使用方法;随后逐步拆解其原理机制,并深入讲解 scikit-learn 的接口实现,让你能够在实际项目中灵活高效地应用 GBDT。
1. 直接上手
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.datasets import make_regression
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
def demo01():
# 生成数据
x, y = make_classification(n_samples=200, random_state=42)
# 分割数据(训练集 80%,测试集 20%)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=42)
# 训练模型
gbdt = GradientBoostingClassifier()
gbdt.fit(x_train, y_train)
# 评估模型
acc = gbdt.score(x_test, y_test)
print('Acc: %.2f' % acc)
def demo02():
# 生成数据
x, y = make_regression(n_samples=200, random_state=42)
# 分割数据(训练集 80%,测试集 20%)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=42)
# 训练模型
gbdt = GradientBoostingRegressor()
gbdt.fit(x, y)
# 评估模型
r2 = gbdt.score(x_test, y_test)
print('R2: %.2f' % r2)
if __name__ == '__main__':
demo01()
demo02()
2. 基本思想
GBDT 的核心思想可以用八个字概括:加法模型 + 梯度优化。这听起来有点抽象,但如果从直观角度去理解,其实并不复杂。
GBDT 加法模型:
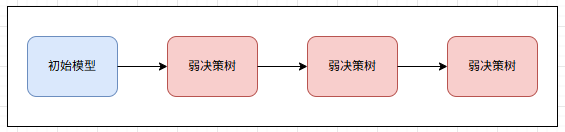
从表面来看,GBDT 是由一个初始模型和多个决策树构成的算法模型。整个模型可以被看作一个由多棵树叠加形成的加法系统:
- 初始模型负责给出最基础的预测结果
- 随后的每棵树,都是在当前模型的基础上,进一步提供补充信息
- 所有树的输出按照一定的权重累加,得到最终预测值
因此,GBDT 并不是一棵大树,而是一组小树组合而成的模型。每棵树结构独立、功能单一,但当它们的输出被整合在一起时,就能形成一个整体预测能力很强的模型。
GBDT 梯度优化:
在 GBDT 中,梯度这个词听起来很数学,但其实它的本质就是一个方向,告诉我们当前模型往哪个方向调整,才能让预测结果更接近真实值。
假设:我们有 100 个样本。第一棵树会先对这 100 个样本做出一轮预测。做完之后,我们自然能看到每个样本的预测结果和真实结果之间的差距,也就是哪里猜得不准、错得多。
接下来,第二棵树就会根据这些差距来学习:它会想办法照顾那些预测不准的样本,尽量在它们身上多做改进。换句话说,第二棵树的作用,就是在前一棵树的基础上,把预测再往更准确的方向推一小步。每一棵树都参考前面模型哪里做得不好,再去补一补。树和树之间是一种接力的关系:前面的树先预测,后面的树不断修正,最终整个模型的预测会越来越精确。
所以,所谓“梯度优化”,其实就是一种有方向地修正误差的过程。每一步都不是随便乱改,而是有目的地朝着“让整体预测更准确”的方向前进。

 冀公网安备13050302001966号
冀公网安备13050302001966号