
1. 模型训练
该代码实现了RNN 训练情感分析模型,主要功能包括:
- 数据预处理:加载数据集,使用
Tokenzier编码,并按长度排序。 - 模型训练:使用
CrossEntropyLoss计算损失,AdamW进行优化,并动态调整学习率。 - 训练流程:循环训练 20 轮,更新参数,记录损失,并保存模型和
tokenizer。 - 结果可视化:绘制损失曲线,观察训练效果。
创建 03-模型训练.py 文件并添加如下代码:
import jieba
import logging
jieba.setLogLevel(logging.CRITICAL)
logging.basicConfig(level=logging.INFO, format="%(levelname)s - %(message)s")
import warnings
warnings.filterwarnings('ignore')
import torch
import torch.nn as nn
import pickle
import torch.optim as optim
from torch.optim.lr_scheduler import StepLR
from torch.utils.data import DataLoader
from tqdm import tqdm
import matplotlib.pyplot as plt
import os
import shutil
from estimator import SentimentAnalysis
from tokenizer import Tokenzier
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# watch -n 10 nvidia-smi
def train():
tokenizer = Tokenzier()
estimator = SentimentAnalysis(vocab_size=tokenizer.get_vocab_size(), num_labels=2, padding_idx=tokenizer.pad).to(device)
criterion = nn.CrossEntropyLoss(reduction='mean')
optimizer = optim.AdamW(estimator.parameters(), lr=1e-4)
scheduler = StepLR(optimizer, step_size=1, gamma=0.85)
train_data = pickle.load(open('data/train.pkl', 'rb'))
def collate_fn(batch_data):
batch_inputs, batch_labels = [], []
for label, data in batch_data:
batch_inputs.append(data)
batch_labels.append(label)
batch_inputs, batch_length = tokenizer.encode(batch_inputs)
# 根据长度由大到小排序
sorted_index = torch.argsort(batch_length, descending=True)
batch_labels = torch.tensor(batch_labels)[sorted_index].to(device)
batch_inputs = batch_inputs[sorted_index].to(device)
batch_length = batch_length[sorted_index]
return batch_inputs, batch_length, batch_labels
total_loss, total_epoch = [], 20
for epoch in range(total_epoch):
epoch_loss, epoch_size = 0, 0
dataloader = DataLoader(dataset=train_data, shuffle=True, batch_size=128, collate_fn=collate_fn)
progress = tqdm(range(len(dataloader)), ncols=100, desc='epoch: %2d loss: %07.2f lr: %.7f' % (0, 0, 0))
for batch_inputs, batch_length, batch_labels in dataloader:
# 推理计算
y_preds = estimator(batch_inputs, batch_length)
# 损失计算
loss = criterion(y_preds, batch_labels)
# 梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 参数更新
optimizer.step()
# 当前损失
epoch_loss += loss.item() * len(batch_labels)
epoch_size += len(batch_labels)
# 更新进度
progress.update()
progress.set_description('epoch: %2d loss: %07.2f lr: %.7f' %
(epoch + 1, epoch_loss, scheduler.get_last_lr()[0]))
progress.close()
# 记录轮次损失
total_loss.append(epoch_loss)
# 更新学习率
scheduler.step()
# 模型存储
save_path = f'model/{epoch + 1}/'
if os.path.exists(save_path) and os.path.isdir(save_path):
shutil.rmtree(save_path)
os.mkdir(save_path)
estimator.save(save_path + 'estimator.bin')
tokenizer.save(save_path + 'tokenizer.bin')
# 绘制损失变化
plt.plot(range(total_epoch), total_loss)
plt.grid()
plt.show()
if __name__ == '__main__':
train()
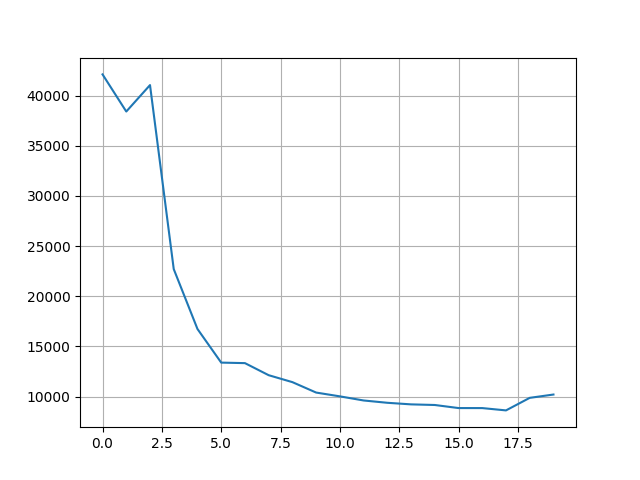
图片展示 20 个 epoch 的在训练集上的总损失变化曲线。随着训练的进行,整体损失呈现下降趋势。
2. 模型评估
该代码实现了情感分析模型评估,主要功能包括:
- 模型加载:根据
model_id加载对应的tokenizer和训练好的模型。 - 数据处理:从测试集加载数据,进行编码并按长度排序。
- 预测与评估:通过模型进行预测,计算预测结果与真实标签的准确率。
- 结果展示:评估多个模型(共21个)并绘制准确率变化曲线。
创建 04-模型评估.py 文件并添加如下代码:
import warnings
warnings.filterwarnings('ignore')
import jieba
import logging
jieba.setLogLevel(logging.CRITICAL)
logging.basicConfig(level=logging.INFO, format="%(levelname)s - %(message)s")
import torch
import pickle
from torch.utils.data import DataLoader
from estimator import SentimentAnalysis
from tokenizer import Tokenzier
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def eval(model_id=5):
if model_id > 0:
tokenizer = Tokenzier.load(f'model/{model_id}/tokenizer.bin')
estimator = SentimentAnalysis.load(f'model/{model_id}/estimator.bin').to(device)
else:
tokenizer = Tokenzier()
estimator = SentimentAnalysis(tokenizer.get_vocab_size(), 2, tokenizer.pad).to(device)
train_data = pickle.load(open('data/test.pkl', 'rb'))
def collate_fn(batch_data):
batch_inputs, batch_labels = [], []
for label, data in batch_data:
batch_inputs.append(data)
batch_labels.append(label)
batch_inputs, batch_length = tokenizer.encode(batch_inputs)
# 根据长度由大到小排序
sorted_index = torch.argsort(batch_length, descending=True)
batch_labels = torch.tensor(batch_labels)[sorted_index].to(device)
batch_inputs = batch_inputs[sorted_index].to(device)
batch_length = batch_length[sorted_index]
return batch_inputs, batch_length, batch_labels
dataloader = DataLoader(dataset=train_data, shuffle=True, batch_size=128, collate_fn=collate_fn)
y_pred, y_true = [], []
for batch_inputs, batch_length, batch_labels in dataloader:
with torch.no_grad():
logits = estimator(batch_inputs, batch_length)
model_labels = torch.argmax(logits, dim=-1)
y_pred.extend(model_labels.tolist())
y_true.extend(batch_labels.tolist())
accuracy = accuracy_score(y_true, y_pred)
print('model: %2d, accuracy: %.3f' % (model_id, accuracy))
return accuracy
def demo():
scores = []
for model_id in range(21):
score = eval(model_id)
scores.append(score)
plt.plot(range(21), scores)
plt.grid()
plt.show()
if __name__ == '__main__':
demo()



 冀公网安备13050302001966号
冀公网安备13050302001966号