
梯度裁剪是一种有效的防止梯度爆炸的技术,特别是在训练深度神经网络和循环神经网络时。它通过限制梯度的大小,使训练过程更加稳定。虽然有时可能会影响收敛速度,但它对于防止训练失败是非常有用的。
1. 梯度爆炸
梯度爆炸是指在反向传播过程中,梯度值变得非常大,导致权重更新过大,从而使得模型的参数变得不稳定,甚至造成训练无法收敛。我们可以通过一些简单的方法来判断是否发生了梯度爆炸。
梯度爆炸通常会导致损失函数(loss)值的异常变化,正常情况下,损失函数应该逐渐减小,波动不会太大。当梯度爆炸发生时,损失函数可能会在训练过程中突然增加,变得非常大。所以,可以通过监控损失函数的大小来检测是否有梯度爆炸的迹象。
另外一种常见的方法是监控梯度的 L2 范数(或其他范数)大小。正常情况下,梯度的范数通常是一个比较稳定的数值,不会随训练的进行剧烈波动。当梯度的范数突然变得非常大,远远超过合理的范围时,就可能发生了梯度爆炸。
2. 梯度控制
梯度爆炸会使得网络无法得到有效训练,我们可以通过对参数梯度值的控制来优化网络训练,常见的方法就是对梯度值进行裁剪。具体可以根据梯度的绝对值进行裁剪,也可以根据梯度的范数进行裁剪。前者思路较为简单,只需要设定一个最大梯度值,当梯度超过该值,则会被裁剪为该值。这种方法简单,但是可能改变参数的优化方向。实际应用时,我们更多的使用基于范数的裁剪方式,具体计算如下:
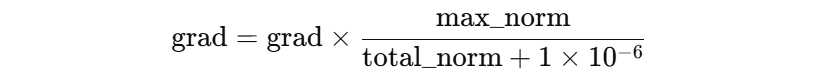
max_norm 是我们期望控制的梯度范数,total_norm 是所有参数梯度的范数,两者的比率作为梯度的缩放因子。
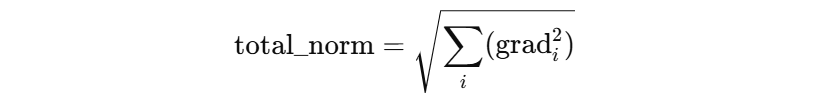
下面给出了 PyTorch 中根据值、和范数裁剪的使用示例:
import torch
import torch.nn as nn
# 1. 数值裁剪
def demo01():
parameters = torch.tensor([1, 2, 3], dtype=torch.float32, requires_grad=True)
parameters.grad = torch.tensor([1, 2, 3], dtype=torch.float32)
print('裁剪前梯度:', parameters.grad)
nn.utils.clip_grad_value_(parameters, clip_value=2)
print('裁剪后梯度:', parameters.grad)
# 2. 范数裁剪
def demo02():
parameters = torch.tensor([1, 2, 3], dtype=torch.float32, requires_grad=True)
parameters.grad = torch.tensor([1, 2, 3], dtype=torch.float32)
print('裁剪前梯度:', parameters.grad)
nn.utils.clip_grad_norm_(parameters, max_norm=1.0)
print('裁剪后梯度:', parameters.grad)
if __name__ == '__main__':
demo01()
print('-' * 30)
demo02()



 冀公网安备13050302001966号
冀公网安备13050302001966号