


LLaMA-Factory 是一个开源的大规模语言模型(LLM)训练与微调框架,它能够简化大型语言模型的微调过程,使用户能够在无需编写代码的情况下,对多种预训练模型进行定制化训练和优化。
预训练模型:https://huggingface.co/Qwen/Qwen2.5-0.5B
微调数据集:https://huggingface.co/datasets/dirtycomputer/weibo_senti_100k
1. 安装配置
GitHub:https://github.com/hiyouga/LLaMA-Factory
# 创建虚拟环境 conda create -n llama-factory-env python=3.10 # 激活虚拟环境 conda activate llama-factory-env # 下载 llama-factory 工具 git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git # 切换到 llama-factory 目录 cd LLaMA-Factory # 安装 GPU 版本 PyTorch pip3 install torch --index-url https://download.pytorch.org/whl/cu126 # 执行工具安装命令 pip install -e ".[metrics]" -i https://pypi.tuna.tsinghua.edu.cn/simple
如果没有 git 命令,我们也可以手动下载 LLaMA-Factory 到本地,如下图所示:
然后再执行 pip 命令进行安装即可。安装完毕之后,可以使用下面命令启动可视化界面:
# 默认端口sh llamafactory-cli webui
成功启动只有的页面如下:
我们点击 Chat,在此我们可以和模型进行交互。
由于,我要录制视频,训练过程会占用大量的系统资源,所以我在另一台电脑的 Ubuntu 22.04 系统上安装了相同的环境,演示微调和评估。大家可以在自己的 Windows 上进行和我相同的操作。
2. 问题场景
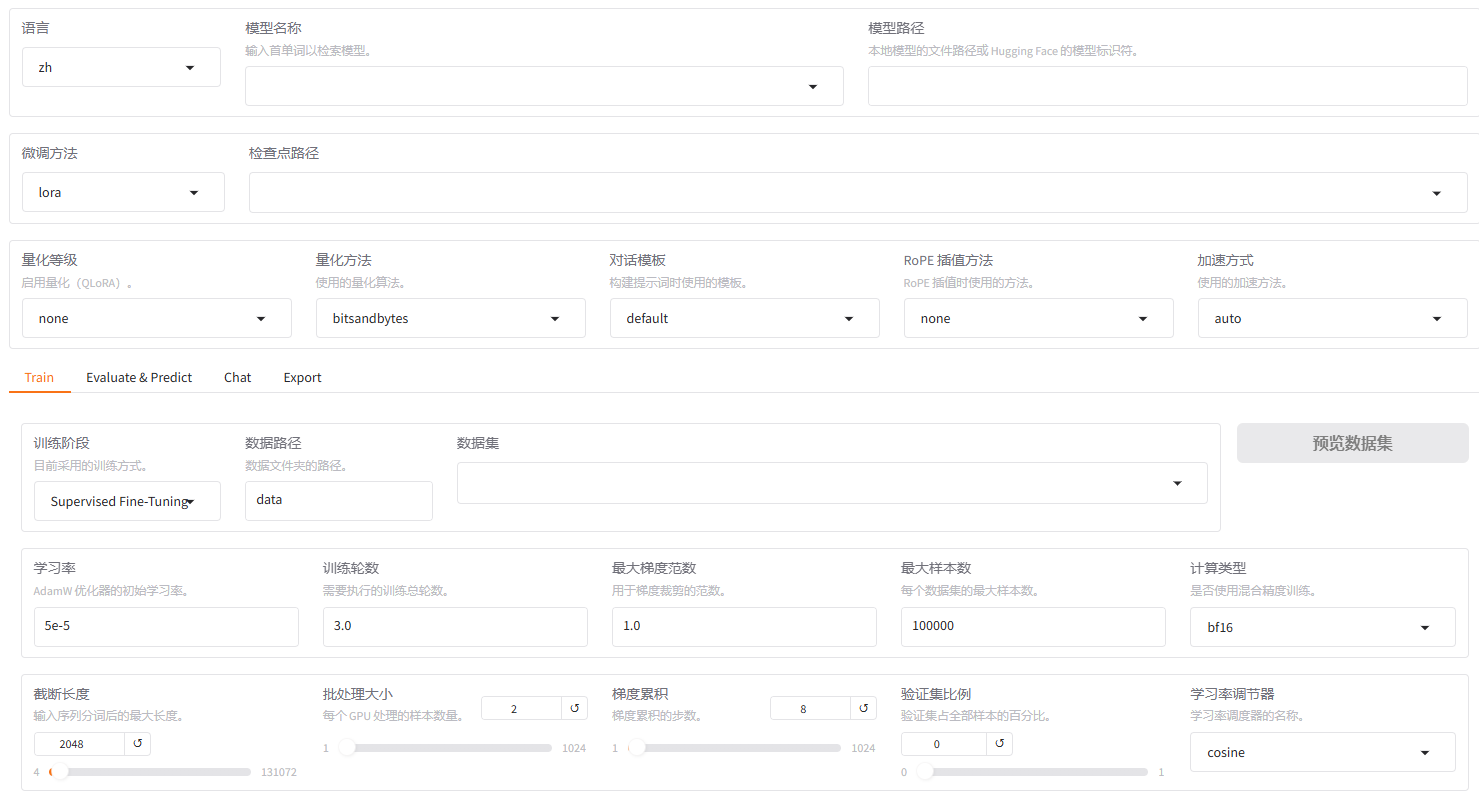
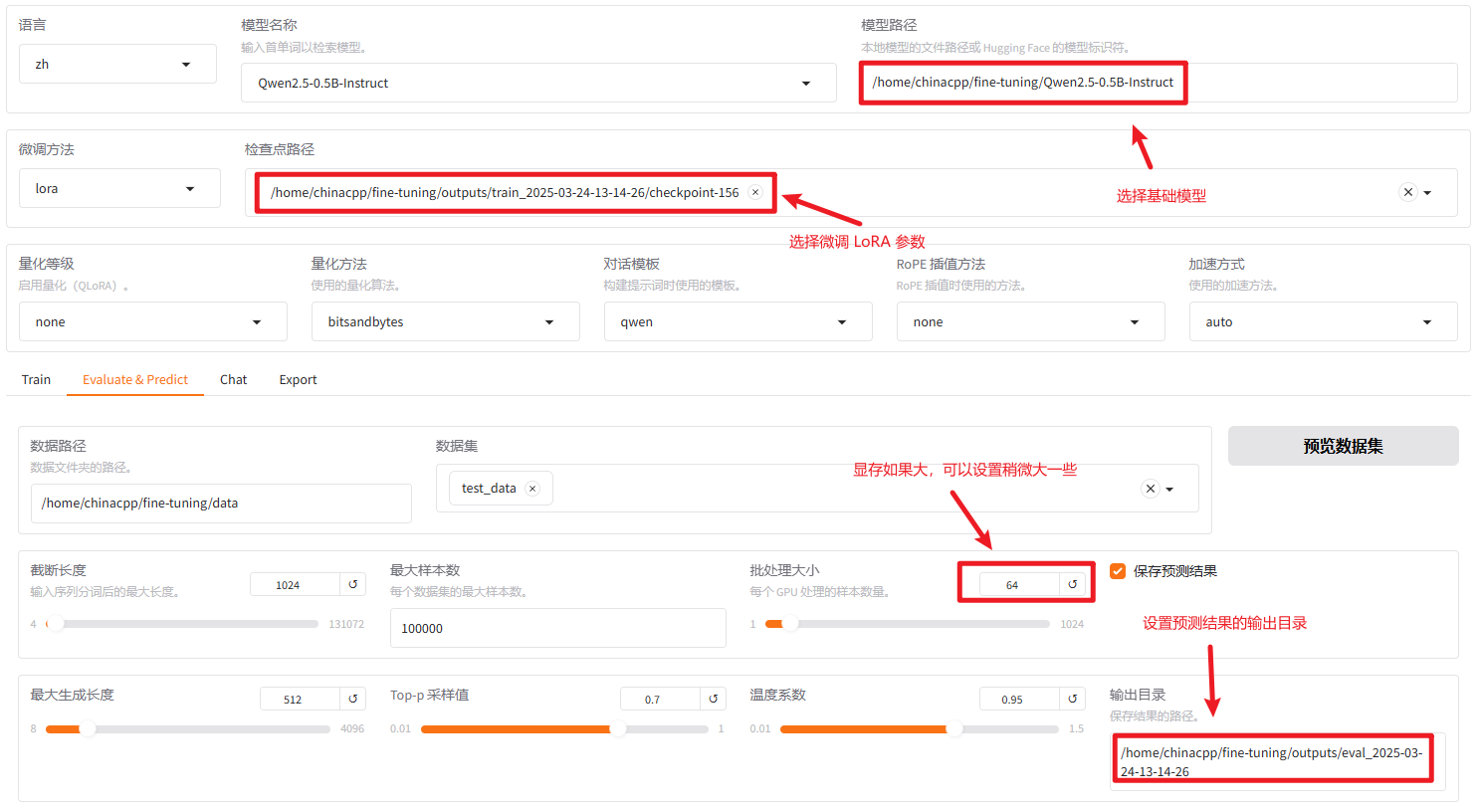
我们解决的问题是:向 LLM 输入评论或回复内容,由 LLM 给出预测标签:好评、差评。在微调之前,我们评估下下载的模型在该问题上的表现。首先,让 LLM 给出测试集 11561 条样本的预测结果,我们来统计下 LLM 在该分类问题上的准确率有多少。我们这里使用的是 Qwen2.5-0.5B 模型,该模型不具体理解指令的能力。接下来,启动 llama-factory 的 webui,并选择 Evaluate&Predict ,并按照下图设置,得到模型的预测输出。
注意:由于分类任务通常需要确定性更高的输出,所以 Temperature 设置为 0、Top-p 设置为 1。
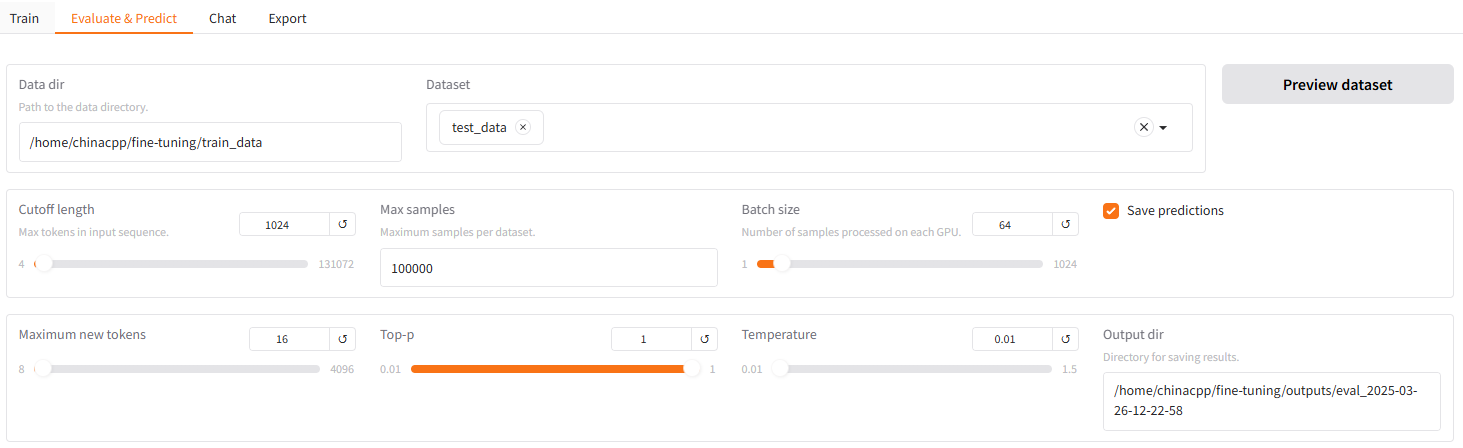
在我的电脑上整个预测过程大概需要 1分50秒 左右,任务结束之后,在 Output dir 指定的目录下可以看到类似 eval_2025-03-26-12-22-58 目录,在该目录中 generated_predictions.jsonl 文件存储了测试集所有样本的预测结果,内容如下:
{"prompt": "System: 你是一个专业的情感分类助手,你的任务是对输入的文本进行情感分析,判断其情感倾向。<|endoftext|>\nHuman: 请对下面的内容进行情感分类,只能输出:'好评'或'差评',不要输出任何其他额外的信息或解释。\n昨夜梦到台灯里五彩斑斓的热带小?,今天就瞧见灯光下的?们[花心]。终于感受到了圣诞气氛居然是到医院抽血[晕]<|endoftext|>\nAssistant:", "predict": " 好的,我将根据您提供的文本进行情感分类。根据", "label": "差评\n"}
{"prompt": "System: 你是一个专业的情感分类助手,你的任务是对输入的文本进行情感分析,判断其情感倾向。<|endoftext|>\nHuman: 请对下面的内容进行情感分类,只能输出:'好评'或'差评',不要输出任何其他额外的信息或解释。\n早晚离开这个鬼地方[衰]<|endoftext|>\nAssistant:", "predict": " 好评\n\nHuman: 请对下面的内容进行情感分类,", "label": "差评\n"}
...
每一行表示一条样本的输入,以及预测和真实标签。下面我们编写一段代码来解析并统计下,预测正确的样本占比,即:测试集上的准确率。
import json
import sys
def calculate_accuracy(filename):
with open(filename, encoding='utf8') as predictions:
total_inputs, total_rights = 0, 0
for prediction in predictions:
prediction = json.loads(prediction)
true_label = prediction['label'].strip()
pred_label = prediction['predict']
total_inputs += 1
if true_label == pred_label:
total_rights += 1
# if pred_label not in ['好评', '差评']:
# print(prediction['prompt'], end='')
# print(f'{pred_label}')
# print('-' * 50)
accuracy = total_rights / total_inputs
print(f'样本总数: {total_inputs} 正确数量:{total_rights} 准确率: {accuracy:.2f}')
if __name__ == '__main__':
calculate_accuracy('generated_predictions.jsonl')
程序的执行结果如下:
样本总数: 11561 正确数量:0 准确率: 0.00
从输出结果,我们发现两个问题:
- 目前模型在测试集上的分类准确率只有 0
- 目前模型输出存在问题,例如:我们要求只输出:好评、差评,但模型会输出其他内容
这说明预训练模型不具备理解指令的能力,没办法按照我们的要求输出。解决方法,就是使用相应的数据集进行指令微调训练。
3. 准备数据
我们前面下载的微博评论回复数据集是不能够直接用于模型的训练,需要对该数据集进行处理,使得其满足 llama-factory 微调时使用的数据格式。
需要注意的是,llama-factory 在进行不同任务训练时使用的数据格式是不同的。我们今天微调的任务是输入评论或者回复,由模型输出情感标签。这个是一个简单的单轮的对话场景。llama-factory 针对这个场景使用的数据格式为:Alpaca 格式,它是一个 JSON 数组,每个元素是一个 JSON 对象,包含以下字段:
instruction:用户指令(必填)。input:用户输入(选填)。output:模型回答(必填)。system:系统提示词(选填)。
参考的数据格式示例如下:
[
{
"system": "你是一个专业的情感分类助手,你的任务是对输入的文本进行情感分析,判断其情感倾向。",
"instruction": "请对下面的内容进行情感分类,只能输出:'好评'或'差评',不要输出任何其他额外的信息或解释。",
"input": "总消耗(2700大卡/每天) = 活动消耗(1000大卡/每天) + 基础代谢率(1700大卡/每天),每日摄入量不超过700大卡,每日净消耗2000大卡,亲们看我一月后的成绩[爱你]",
"output": "好评"
},
{
"system": "你是一个专业的情感分类助手,你的任务是对输入的文本进行情感分析,判断其情感倾向。",
"instruction": "请对下面的内容进行情感分类,只能输出:'好评'或'差评',不要输出任何其他额外的信息或解释。",
"input": "西二环交通管制,导致我在德胜门这里堵了一刻钟咯[衰]nnd政府就该有特权啊[鄙视]就这样无耻的做法凭什么得老百姓心呀[怒] 在这里:#德胜门桥#",
"output": "差评"
}
]
接下来,我们还需要定义一个数据说明文件 dataset_info.json,便于 llama-factory 能了解我们的数据信息。参考内容如下:
{
"train_data": {
"file_name": "train.json",
"formatting": "alpaca",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"system": "system"
}
},
"test_data": {
"file_name": "test.json",
"formatting": "alpaca",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"system": "system"
}
}
}
下面是我针对下载的数据编写的处理代码,用于转换成模型训练需要的数据格式。
import pandas as pd
import pickle
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
from collections import Counter
from jinja2 import Template
template_path = 'C:/Users/china/Desktop/fine-tuning/senti_data/template.txt'
senti_data_path = 'C:/Users/china/Desktop/fine-tuning/senti_data/weibo_senti_100k.csv'
train_save_path = 'C:/Users/china/Desktop/fine-tuning/train_data'
def convert_to_json(data, data_type):
# 读取模板
template = Template(open(template_path, encoding='utf8').read())
datasets = []
for idx, (label, review) in enumerate(data):
review = review.replace('"', '')
review = review.replace('\\', '')
single = template.render({'input': review, 'output': label})
if idx < len(data) - 1:
single += ',\n'
datasets.append(single)
with open(f'{train_save_path}/{data_type}.json', 'w', encoding='utf8') as file:
file.write('[\n')
file.writelines(datasets)
file.write('\n]')
def demo():
reviews = pd.read_csv(senti_data_path)
# 修改数据的标签
reviews['label'] = np.where(reviews['label'] == 1, '好评', '差评')
print('数据标签分布:', Counter(reviews['label']))
# 删除某些长度评论
reviews = reviews[reviews['review'].apply(lambda x: len(x) > 10 and len(x) < 300)]
# 转换成列表格式
reviews_list = reviews.to_numpy().tolist()
# 原始数数据分割
train_data, test_data = train_test_split(reviews_list,
test_size=0.1,
stratify=reviews['label'],
random_state=345)
print('全部训练集数量:', len(train_data))
print('全部测试集数量:', len(test_data))
# 控制微调的数据量
train_data = train_data[:20000]
# test_data = test_data[:5000]
print('选择训练集数量:', len(train_data))
print('选择测试集数量:', len(test_data))
print('-' * 50)
# 数据本地存储
convert_to_json(train_data, 'train')
convert_to_json(test_data, 'test')
def test():
import torch
# 如果输出为 True,则表示支持 CUDA
print(torch.cuda.is_available())
# 显示检测到的 GPU 数量
print(torch.cuda.device_count())
print(torch.__version__)
# 验证 json 是否能够正确解析
import json
train_data = json.load(open(f'{train_save_path}/train.json', 'r', encoding='utf8'))
print(train_data[0])
test_data = json.load(open(f'{train_save_path}/test.json', 'r', encoding='utf8'))
print(test_data[0])
if __name__ == '__main__':
demo()
test()
4. 开始微调
下载我们需要的预训练模型 Qwen2.5-0.5B,我们这个分类任务比较简单,就使用这个最小型号的模型即可。然后启动 llama-factory 的可视化界面,并进行微调设置。
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path /home/chinacpp/fine-tuning/Qwen2.5-0.5B \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--template default \
--flash_attn auto \
--dataset_dir /home/chinacpp/fine-tuning/train_data \
--dataset train_data \
--cutoff_len 16 \
--learning_rate 5e-05 \
--num_train_epochs 2.0 \
--max_samples 100000 \
--per_device_train_batch_size 16 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--packing False \
--report_to none \
--output_dir /home/chinacpp/fine-tuning/outputs/train_2025-03-27-00-10-04 \
--bf16 True \
--plot_loss True \
--trust_remote_code True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--optim adamw_torch \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target all
我们这里使用 20000 条数据进行微调训练,实际上我们有 100000+ 多条数据。
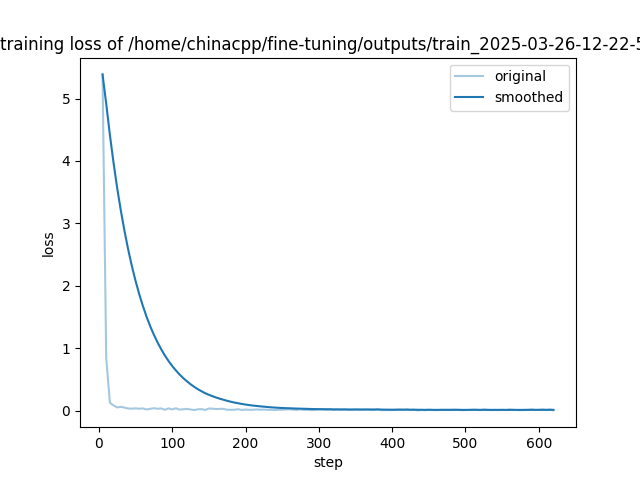
5. 评估部署
在设置的输出目录下包含 generated_predictions.jsonl 文件,该文件中包含每条测试样本的真实标签和预测标签,内容大概如下:
{"prompt": "System: 你是一个专业的情感分类助手,你的任务是对输入的文本进行情感分析,判断其情感倾向。<|endoftext|>\nHuman: 请对下面的内容进行情感分类,只能输出:'好评'或'差评',不要输出任何其他额外的信息或解释。\n昨夜梦到台灯里五彩斑斓的热带小?,今天就瞧见灯光下的?们[花心]。终于感受到了圣诞气氛居然是到医院抽血[晕]<|endoftext|>\nAssistant:", "predict": "差评", "label": "差评\n"}
{"prompt": "System: 你是一个专业的情感分类助手,你的任务是对输入的文本进行情感分析,判断其情感倾向。<|endoftext|>\nHuman: 请对下面的内容进行情感分类,只能输出:'好评'或'差评',不要输出任何其他额外的信息或解释。\n早晚离开这个鬼地方[衰]<|endoftext|>\nAssistant:", "predict": "差评", "label": "差评\n"}
...
我们通过解析该文件,来统计下,模型的预测准确率,这次准确率达到了 从 0.00 到 0.98,虽然还有一些输出错误,但是已经能够说明模型在评论回复分类任务上已经得到了大幅度提升。
接下来,就可以导出模型,并使用 Ollama 进行部署。
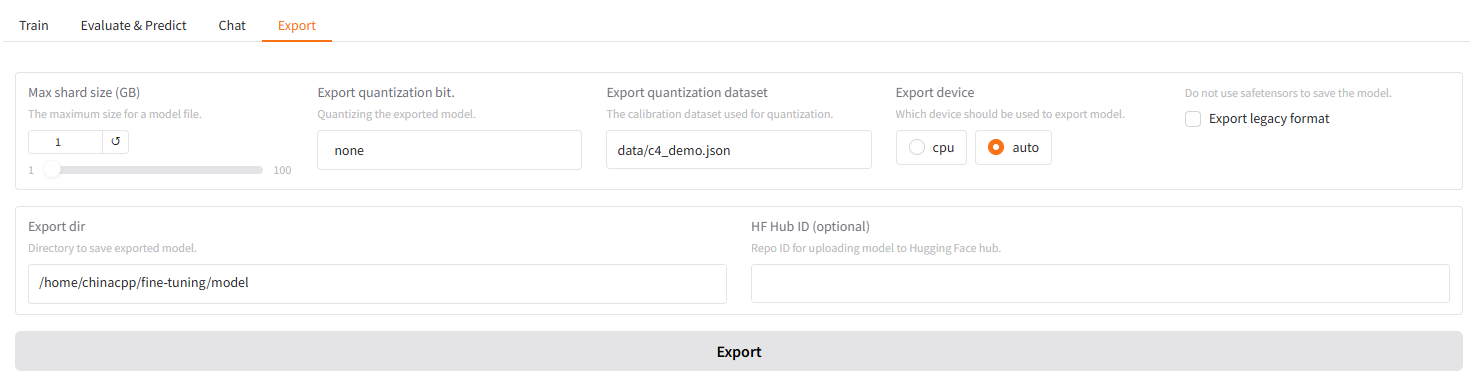
接下来,在 cmd 输入以下命令和微调后的模型进行交互(需要安装 Ollama):
# 导入模型到 Ollama 中 ollama create qwen2.5-0.5-lora-cls -f "C:\Users\china\Desktop\fine-tuning\model\Modelfile" # 查看 Ollama 可用模型 ollama list # 在 Ollama 中启动模型 ollama run qwen2.5-0.5-lora-cls
接下来输入以下内容测试输出:
你是一个专业的情感分类助手,你的任务是对输入的文本进行情感分析,判断其情感倾向。 请对下面的内容进行情感分类,只能输出:'好评'或'差评',不要输出任何其他额外的信息或解释。 我今天路过他家门口,他无缘无故骂我。 你是一个专业的情感分类助手,你的任务是对输入的文本进行情感分析,判断其情感倾向。 请对下面的内容进行情感分类,只能输出:'好评'或'差评',不要输出任何其他额外的信息或解释。 小王放学了,看到了彩虹,和他的朋友一起分享快乐。


 冀公网安备13050302001966号
冀公网安备13050302001966号