


在自然语言处理(NLP)里,中英翻译是个常见的任务。但中文和英文在 语法、词序、表达方式 上差别很大,所以想要让机器做好翻译并不容易。不过,随着大模型技术的发展,这个难题已经比以前简单了很多。
现在,我们可以利用 mT5(Multilingual T5) 这样的预训练模型来完成翻译任务。mT5 是 Google 推出的一个多语言文本生成模型,支持 100 多种语言,不仅能做机器翻译,还能用于文本摘要、问答等任务。我们可以对它进行 微调(Fine-tuning),让它更适应中文到英文的翻译,提高流畅度和准确性。
接下里,我们就从以下几个步骤来实现中文到英文的翻译:
- 数据处理:如何准备和清理中英翻译数据集。
- 模型训练:如何进行微调适应中文到英文的翻译任务。
- 模型推理:如何用训练好的模型进行文本翻译。
- 模型评估:如何衡量翻译质量,优化模型性能。
1. 数据处理
import logging
logging.basicConfig(level=logging.ERROR)
import warnings
warnings.filterwarnings('ignore')
import numpy as np
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
from transformers import AutoModel
import json
import torch
import pickle
from tqdm import tqdm
device = torch.device('cuda')
encoder = AutoModel.from_pretrained('jina-embeddings-v3', trust_remote_code=True).to(device)
def clean_text(cn, en):
# 输入长度大于500,小于3的删除
if len(cn) <= 2 or len(cn) > 500 or len(en) == 0:
return False
# 包含反斜杠的内容删除
if '\\' in en or '\\' in cn:
return False
# 相似度低于0.5的删除
# vectors = encoder.encode([en, cn], convert_to_tensor=True, task='text-matching')
# score = torch.matmul(vectors[0], vectors[1])
# if score < 0.5:
# return False
return True
def length_curve(cn_lens, en_lens):
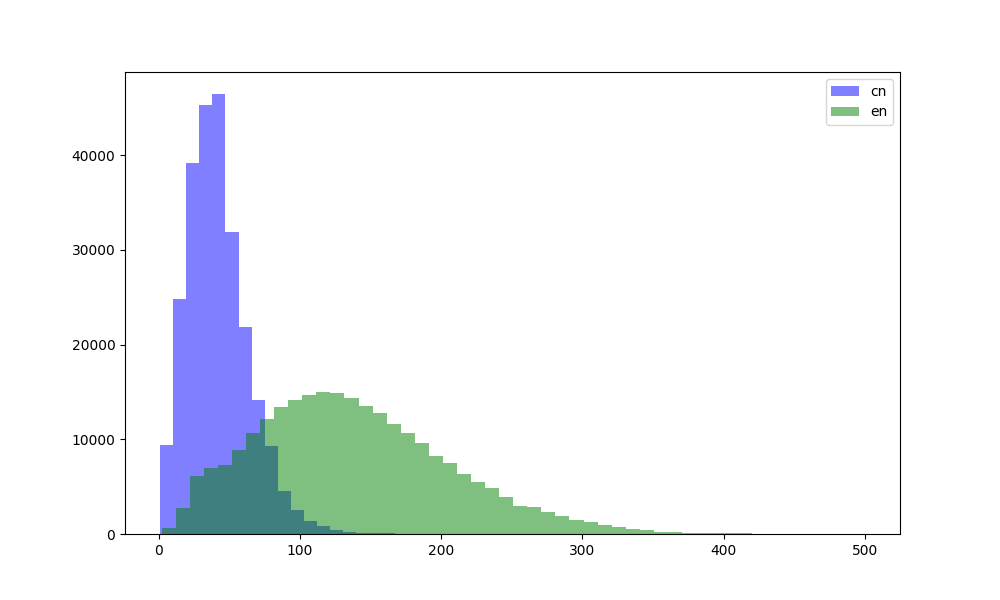
print('中文:', max(cn_lens), min(cn_lens))
print('英文:', max(en_lens), min(en_lens))
plt.figure(figsize=(10, 6))
plt.hist(cn_lens, bins=50, alpha=0.5, label="cn", color='blue')
plt.hist(en_lens, bins=50, alpha=0.5, label="en", color='green')
plt.legend()
plt.show()
def split_corpus(cn_en_data):
train_data = cn_en_data[:-50000]
test_data = cn_en_data[-50000:]
pickle.dump(train_data, open('data/trans-train.pkl', 'wb'))
pickle.dump(test_data, open('data/trans-test.pkl', 'wb'))
print('训练集:', len(train_data))
print('测试集:', len(test_data))
print(test_data[:3])
def demo():
# 读取中英翻译语料
fnames = [f'translation-data/{data_type}.json' for data_type in ['train', 'dev', 'test']]
all_data = [item for fname in fnames for item in json.load(open(fname))]
# 语料清洗,长度统计
cn_lens, en_lens, cn_en_data = [], [], []
for en, cn in tqdm(all_data):
en, cn = en.strip(), cn.strip()
if not clean_text(cn, en):
continue
cn_lens.append(len(cn))
en_lens.append(len(en))
cn_en_data.append((cn, en))
# 绘制长度分布
length_curve(cn_lens, en_lens)
# 分割存储语料
split_corpus(cn_en_data)
if __name__ == '__main__':
demo()
中文: 463 3
英文: 1027 3
训练集: 202605
测试集: 50000
[('正确的应对方式是什么?', 'What is the right response to a collapse?'), ('明年的巴黎联合国气候变化会议(COP21)将是一场重要考验。', 'A major test will be next year’s United Nations climate change conference (COP21) in Paris.'), ('香港—中国国务院最近发布了2020年资本市场改革的若干意见,其中提出了两个关键目标:“维护公开、公平、公正的市场秩序,保护投资者特别是中小投资者的合法权益。', 'HONG KONG – China’s State Council recently unveiled a comprehensive blueprint for capital-market reform until 2020, in which it identifies two key objectives: “to support open, fair, and integral market processes, and to protect investors, particularly the legal rights of small investors.”')]
2 模型训练
使用 20+万 中文=> 英文的语料进行训练,共计训练 3 个 epoch,6 小时左右。
from transformers import logging
logging.set_verbosity_error()
from transformers import T5Tokenizer
from transformers import MT5ForConditionalGeneration
from ignite.engine import Engine
from ignite.engine import Events
from ignite.engine import State
from tqdm import tqdm
import torch.optim as optim
import torch.nn as nn
from torch.utils.data import DataLoader
from ignite.contrib.handlers import ProgressBar
from ignite.handlers import Checkpoint
import torch
import pickle
import os
import shutil
def train():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
tokenizer = T5Tokenizer.from_pretrained('mt5-small', legacy=True)
estimator = MT5ForConditionalGeneration.from_pretrained('mt5-small').to(device)
optimizer = optim.AdamW(estimator.parameters(), lr=1e-4)
criterion = nn.CrossEntropyLoss(ignore_index=tokenizer.pad_token_id)
def train_step(engine, batch_inputs):
estimator.train()
batch_inputs = { k: v.to(device) for k, v in batch_inputs.items()}
outputs = estimator(**batch_inputs)
optimizer.zero_grad()
outputs.loss.backward()
optimizer.step()
size = torch.sum(batch_inputs['labels'] != 0).item()
loss = outputs.loss.item()
return {'loss': loss * size, 'size': size}
trainer = Engine(train_step)
def collate_fn(batch_data):
srcs, tgts = [], []
for src, tgt in batch_data:
srcs.append(src)
tgts.append(tgt)
batch_inputs = tokenizer(srcs, text_target=tgts,
padding=True,
truncation=True,
max_length=500,
return_tensors='pt')
return batch_inputs
train_data = pickle.load(open('data/trans-train.pkl', 'rb'))
dataloader = DataLoader(train_data, batch_size=4, shuffle=False, collate_fn=collate_fn)
# 显示进度条
def output_transform(engine):
current_loss = engine.custom['total_loss'] / engine.custom['total_size']
return {'Loss': '%.5f' % current_loss}
progress = ProgressBar()
progress.attach(trainer, output_transform=lambda engine: output_transform(trainer))
# 自动保存检查点
@trainer.on(Events.ITERATION_COMPLETED(every=25000))
def save_checkpoint(engine):
fname = f'model/translation-{engine.state.epoch}-{engine.state.iteration}'
if os.path.exists(fname) and os.path.isdir(fname):
shutil.rmtree(fname)
os.mkdir(fname)
estimator.save_pretrained(fname)
tokenizer.save_pretrained(fname)
@trainer.on(Events.ITERATION_COMPLETED(every=10000))
def predict(engine):
texts = [('正确的应对方式是什么?', 'What is the right response to a collapse?'),
('明年的巴黎联合国气候变化会议(COP21)将是一场重要考验。', 'A major test will be next year’s United Nations climate change conference (COP21) in Paris.'),
('香港—中国国务院最近发布了2020年资本市场改革的若干意见,其中提出了两个关键目标:“维护公开、公平、公正的市场秩序,保护投资者特别是中小投资者的合法权益。', 'HONG KONG – China’s State Council recently unveiled a comprehensive blueprint for capital-market reform until 2020, in which it identifies two key objectives: “to support open, fair, and integral market processes, and to protect investors, particularly the legal rights of small investors.”')]
with open('trans-log.txt', 'a') as file:
file.write('-' * 45 + f'Epoch {engine.state.epoch}-{engine.state.iteration}' + '-' * 45 + '\n\n' )
for src, tgt in texts:
inputs = tokenizer([src], return_tensors='pt')
inputs = {k: v.to(device) for k, v in inputs.items()}
with torch.no_grad():
outputs = estimator.generate(**inputs, max_length=128)
output_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
file.write(f'原文: {src}\n参考: {tgt}\n翻译: {output_text}\n\n\n')
# 训练事件处理
@trainer.on(Events.EPOCH_STARTED)
def on_epoch_started(engine):
# 初始化标记数量和总损失
engine.custom = {}
engine.custom['total_size'] = 1
engine.custom['total_loss'] = 0
@trainer.on(Events.ITERATION_COMPLETED)
def on_iteration_completed(engine):
# 记录当前标记数量和总损失
step_output = engine.state.output
engine.custom['total_size'] += step_output['size']
engine.custom['total_loss'] += step_output['loss']
trainer.run(dataloader, max_epochs=2)
if __name__ == '__main__':
train()
3. 中英翻译
import torch.cuda
from transformers import MT5ForConditionalGeneration
from transformers import T5Tokenizer
def demo():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
modelpath = 'model/translation-2-75000'
tokenizer = T5Tokenizer.from_pretrained(modelpath)
estimator = MT5ForConditionalGeneration.from_pretrained(modelpath).eval().to(device)
while True:
inputs = input('请输入中文:')
if inputs == 'exit':
break
inputs = tokenizer([inputs], return_tensors='pt')
inputs = {k: v.to(device) for k, v in inputs.items()}
with torch.no_grad():
outputs = estimator.generate(**inputs, max_length=128)
output_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print('翻译:', output_text)
print('-' * 50)
if __name__ == '__main__':
demo()
4. 模型评估
使用 5+万 中文=> 英文的语料进行评估。
import numpy as np
import torch.cuda
from transformers import MT5ForConditionalGeneration
from transformers import T5Tokenizer
import rouge
import pickle
from torch.utils.data import DataLoader
from tqdm import tqdm
def evaluate():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
modelpath = 'model/translation-2-100000'
tokenizer = T5Tokenizer.from_pretrained(modelpath)
estimator = MT5ForConditionalGeneration.from_pretrained(modelpath).eval().to(device)
evaluator = rouge.Rouge(metrics=['rouge-1', 'rouge-2', 'rouge-l'], stats=['r',])
def collate_fn(batch_data):
srcs, tgts = [], []
for src, tgt in batch_data:
srcs.append(src)
tgts.append(tgt)
srcs = tokenizer(srcs, padding=True, return_tensors='pt')
srcs = {k: v.to(device) for k, v in srcs.items()}
return srcs, tgts
test_data = pickle.load(open('data/trans-test.pkl', 'rb'))
print('评估数据量:', len(test_data))
dataloader = DataLoader(test_data, batch_size=64, shuffle=True, collate_fn=collate_fn)
rouge_1, rouge_2, rouge_l = [], [], []
progress = tqdm(range(len(dataloader)), 'Evaluate')
for srcs, tgts in dataloader:
with torch.no_grad():
outputs = estimator.generate(**srcs, max_length=128)
output_text = tokenizer.batch_decode(outputs, skip_special_tokens=True)
scores = evaluator.get_scores(output_text, tgts)
for score in scores:
rouge_1.append(score['rouge-1']['r'])
rouge_2.append(score['rouge-2']['r'])
rouge_l.append(score['rouge-l']['r'])
progress.update()
progress.close()
print('rouge-1 recall: %.5f' % np.mean(rouge_1))
print('rouge-2 recall: %.5f' % np.mean(rouge_2))
print('rouge-l recall: %.5f' % np.mean(rouge_l))
if __name__ == '__main__':
evaluate()
 冀公网安备13050302001966号
冀公网安备13050302001966号