


在传统的文本分类任务中,我们通常依赖监督学习方法,比如朴素贝叶斯、支持向量机,或者 BERT 这样的深度学习模型。但这些方法存在三个关键限制:
- 需要固定的分类标签
- 需要大量的标注数据
- 需要不断训练和调参
这种传统方法的不足之处:
- 只能识别预先定义好的标签。例如,我们可能训练了一个分类器来识别”科技”、”体育”新闻类型。但如果后来需要新增”军事”类,就必须重新收集训练数据,重新训练模型。
- 面对多标签分类时也显得力不从心。例如,一则新闻既包含”体育”又涉及”政治”,传统模型往往难以准确识别其多重属性。
简言之:基于传统的方法,一旦标签发生变化,就需要收集新的标注数据、重新训练模型。
那么,有没有一种方式,不依赖大量标注数据,不用频繁训练模型,还能灵活应对标签的变化的文本分类任务实现方法?
答案是有的。
接下来,我将会给大家介绍 基于文本向量模型的零样本分类(Zero-Shot Classification) 方法。这种分类方法有三个优势:
- 无需额外训练数据
- 可动态适配新标签
- 可支持多标签识别
注意:零样本意思是不需要额外的训练数据。
接下来,我们将先讲解核心实现思路,再通过实战代码一步步落地这个技术,让你真正掌握这种文本分类方法的实现方法。
1. 实现思路
文本向量模型是把文本(如词语、句子)转换成数字向量的模型,目的是让计算机能理解和处理文本的语义信息。例如:
- 我喜欢苹果 => [0.21, 0.53, -0.12]
- 苹果 => [0.20, 0.50, -0.10]
向量表示可以捕捉文本的语义信息。语义相近的文本,其向量通常距离较近;语义不相近的文本,其向量距离较远。这使得计算机能够通过向量计算来理解文本之间的语义关系。通常我们衡量文本向量的距离关系时,使用的是余弦相似度(Cosine Similarity),其公式如下:
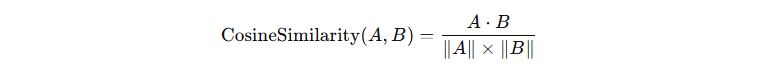
其中:
- \( A·B \) 表示两个向量的点积
- \( ||A|| \) 和 \( ||B|| \) 表示向量 A、B 向量的模(长度);
在自然语言处理中,余弦相似度的值一般都在 [0, 1] 之间,1 表示相似,0 表示不相似。
我们今天探讨如何基于文本向量模型来实现文本分类任务,其思路如下:
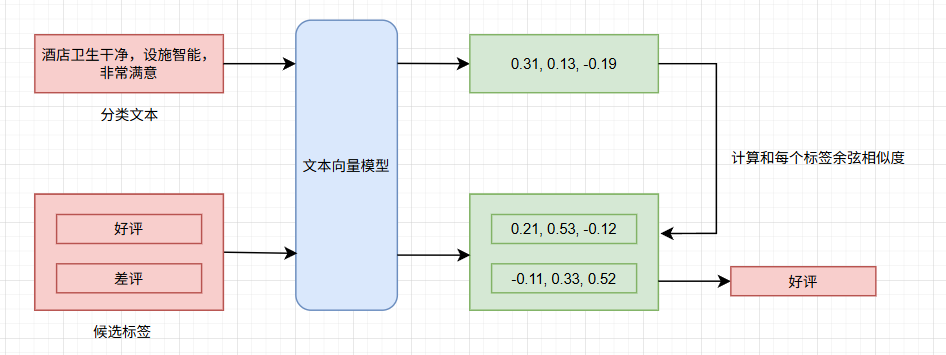
文本向量模型,我们可以选择在线的模型,也可以使用本地模型。我们就使用 jina-embeddings-v3 这个模型,下载地址:
https://huggingface.co/jinaai/jina-embeddings-v3
https://huggingface.co/jinaai/xlm-roberta-flash-implementation/tree/main
接下来,创建一个专门用于文本分类的虚拟环境,并安装依赖的包,具体操作如下:
conda create -n zsl-env python=3.10 pip install torch --index-url https://download.pytorch.org/whl/cu126 pip install transformers pip install einops
2. 具体实现
我们先通过一小段代码来了解如何加载和使用 jina-embeddings-v3 模型将输入文本编码为向量表示,如下代码:
import torch
from transformers import AutoModel
def test():
# 根据模型中的 config.json 配置文件加载模型
encoder = AutoModel.from_pretrained('jina-embeddings-v3', trust_remote_code=True)
# 调用 encode 方法将文本转换为数值向量
# convert_to_tensor:返回张量类型,默认返回 numpy 数组
# task:表示转换后的向量将被用于分类任务
# 注意:模型返回的向量经过归一化,计算相似度时不需要再除以模长
vectors = encoder.encode(['我喜欢苹果'], convert_to_tensor=True, task='classification')
print('向量模型:', type(encoder))
print('向量类型:', type(vectors))
print('向量形状:', vectors.shape)
print('向量数值:', vectors)
if __name__ == '__main__':
test()
向量模型: <class 'transformers_modules.jinaai.xlm-roberta-flash-implementation.2b6bc3f30750b3a9648fe9b63448c09920efe9be.modeling_lora.XLMRobertaLoRA'> 向量类型: <class 'torch.Tensor'> 向量形状: torch.Size([1, 1024]) 向量数值: tensor([[ 0.0416, -0.1188, 0.0370, ..., 0.0175, -0.0205, 0.0119]])
接下来,封装一个类 TextClassificationModel,该类实现 encode、similarity、forward 三个函数
- encode 用于将输入的文本转换为向量
- similarity 用于计算两个向量的余弦相似度
- forward 用于输出预测的标签
在这个过程中,encode 使用 jina-embeddings-v3 模型来实现对输入文本的向量化编码。
import logging
logging.basicConfig(level=logging.ERROR)
import torch.nn as nn
import torch
import numpy as np
from transformers import AutoModel
class TextClassificationModel(nn.Module):
def __init__(self):
super(TextClassificationModel, self).__init__()
# 加载文本向量模型
self.encoder = AutoModel.from_pretrained('jina-embeddings-v3', trust_remote_code=True)
def encode(self, texts):
# 对输入文本进行编码
embeddings = self.encoder.encode(texts, convert_to_tensor=True, task='classification')
return embeddings
def similarity(self, text_embeddings, label_embeddings):
# 计算两个向量的相似度
return torch.matmul(text_embeddings, label_embeddings.T)
def forward(self, texts, labels):
# 1. 对输入的文本和候选标签进行编码
inputs_embeddings = self.encode(texts)
labels_embeddings = self.encode(labels)
# 2. 计算文本和每个候选标签的相似度
class_sim = self.similarity(inputs_embeddings, labels_embeddings)
# 3. 选择相似度最高的标签作为输出
class_id = torch.argmax(class_sim, axis=-1)
labels = labels[class_id.item()]
return labels
if __name__ == '__main__':
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
estimator = TextClassificationModel().to(device)
texts = [('苹果公司今天发布了全新的 iPhone 15 Pro,这款手机配备了更强大的 A17 芯片和全新的摄像头系统,支持 8K 视频拍摄。', ['科技新闻', '体育赛事', '娱乐动态', '商业财经']),
('昨天晚上,我在家里看了一部科幻电影《星际穿越》,电影里宏大的宇宙场景和深刻的情感主题让我深受感动。', ['科幻电影', '历史纪录片']),
('最近,科学家们在火星表面发现了一种新的矿物质,这种矿物质可能为火星上存在过生命的假设提供了新的线索。', ['太空探索', '娱乐新闻', '科技发明']),
('很失望的一次住宿体验。房间有异味,空调不制冷,而且酒店的位置很偏僻,交通不便。服务态度也很差,投诉后也没有得到解决。不会再来了。', ['好评', '差评'])]
for text, label in texts:
pred = estimator([text], label)
print('文本内容:', text)
print('候选标签:', label)
print('预测标签:', pred)
print('-' * 30)
文本内容: 苹果公司今天发布了全新的 iPhone 15 Pro,这款手机配备了更强大的 A17 芯片和全新的摄像头系统,支持 8K 视频拍摄。 候选标签: ['科技新闻', '体育赛事', '娱乐动态', '商业财经'] 预测标签: ['科技新闻'] ------------------------------ 文本内容: 昨天晚上,我在家里看了一部科幻电影《星际穿越》,电影里宏大的宇宙场景和深刻的情感主题让我深受感动。 候选标签: ['科幻电影', '历史纪录片'] 预测标签: ['科幻电影'] ------------------------------ 文本内容: 最近,科学家们在火星表面发现了一种新的矿物质,这种矿物质可能为火星上存在过生命的假设提供了新的线索。 候选标签: ['太空探索', '娱乐新闻', '科技发明'] 预测标签: ['太空探索'] ------------------------------ 文本内容: 很失望的一次住宿体验。房间有异味,空调不制冷,而且酒店的位置很偏僻,交通不便。服务态度也很差,投诉后也没有得到解决。不会再来了。 候选标签: ['好评', '差评'] 预测标签: ['差评'] ------------------------------

 冀公网安备13050302001966号
冀公网安备13050302001966号