
在机器学习中,岭回归(Ridge Regression)是一种常用的回归分析方法,它是线性回归的一种变体,通过引入正则化来减小模型的复杂度,防止过拟合,尤其在特征数多且存在多重共线性问题时,岭回归能有效提高预测精度。
1. 目标函数
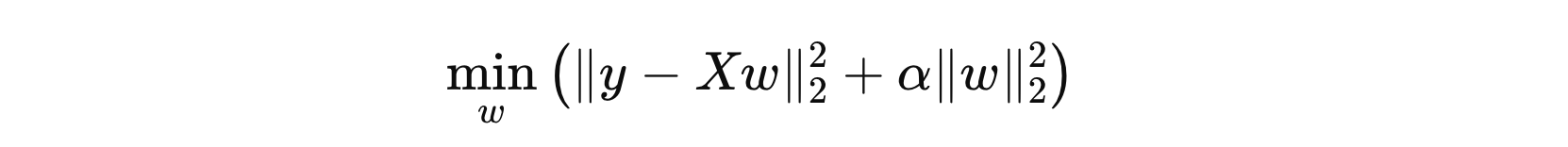
其中:
- \( y \) 表示目标值
- \( X \) 表示特征矩阵,即:所有输入数据
- \( w \) 表示权重向量
- \( α \) 用于控制正则化强度
岭回归的目标就是通过调整权重 \( w \) 来最小化上述目标函数。
2. 正则化项
目标函数中的第二部分是 L2正则化项:
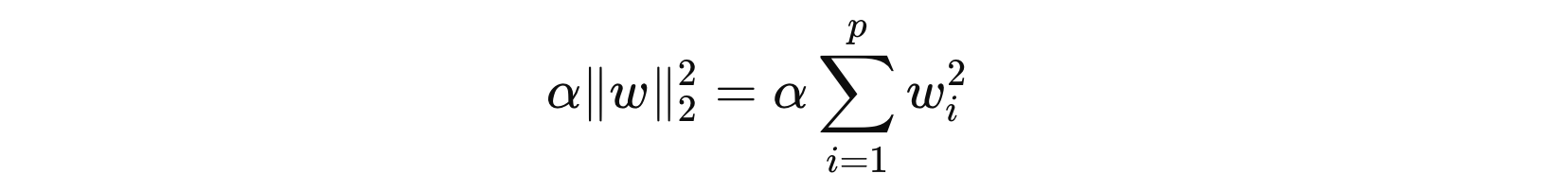
L2 正则化项通过对权重系数进行惩罚,抑制它们的值过大,从而避免模型对某些特征的过度依赖。当设置较大的 \( α \) 值时,将会强烈惩罚特征权重,促使它们接近零,进而降低模型的复杂度,防止过拟合。
3. 算法使用
from sklearn.linear_model import Ridge
from sklearn.datasets import make_regression
def demo():
# 构建数据
X, y = make_regression(n_samples=100, n_features=5, noise=0.1, random_state=42)
# 参数求解
alphas = [0, 0.1, 1, 10, 100]
for alpha in alphas:
estimator = Ridge(alpha=alpha)
estimator.fit(X, y)
print('%.2f\t' % alpha, estimator.coef_)
if __name__ == '__main__':
demo()
0.00 [60.59000738 98.65432927 64.55891226 57.05696343 35.60947647] 0.10 [60.53113208 98.53945847 64.44656151 56.99121806 35.58873414] 1.00 [60.00694188 97.51793602 63.45136759 56.40717681 35.40203643] 10.00 [55.26781953 88.38736703 54.86756091 51.23086241 33.55556133] 100.00 [31.47243879 46.01301466 22.22487976 27.55999345 20.92963551]
在 scikit-learn 中,Ridge 回归的正则化系数 α(alpha)是一个非负值(即 α ∈ [0, ∞])。α 的值越大,对模型权重的惩罚力度越大,导致权重的值越小。这有助于防止模型在存在异常数据时权重过大,从而减小过拟合的风险。



 冀公网安备13050302001966号
冀公网安备13050302001966号