
在自然语言处理(NLP)中,语言模型的评估是衡量模型表现的重要步骤之一。评估指标多种多样,而其中困惑度(Perplexity)是最常用的评估方法之一。
简单来说,困惑度(Perplexity)是衡量语言模型对给定文本的 “困惑” 程度的指标。它反映了模型对语言数据的预测能力。具体而言,困惑度越低,模型的表现就越好,表明它能够更准确地预测文本中的词汇。
可以把困惑度想象成模型面对一个序列时的“困惑程度”。如果模型很容易预测下一个词,那么它就不困惑,困惑度较低;反之,如果模型的预测不准确,困惑度就会较高。
困惑度计算公式如下:
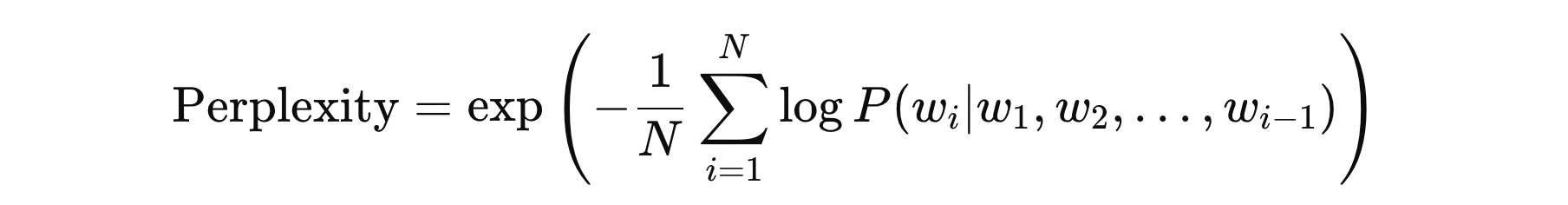
其中:
- \( N \) 表示文本中的总 Token 数量
- \( P(w_{i} | w_{1}, w_{2} .. w_{i-1}) \) 是模型预测的第 \( i \) 个词 \( w_{i} \) 在给定上下文下的条件概率
下面是 awq.evaluation.evaluate_perplexity 中对困惑度计算的实现,我只是修改了下数据加载部分的代码。
import torch
import torch.nn as nn
from tqdm import tqdm
import pickle
def evaluate_perplexity(estimator, tokenizer):
def _perplexity(nlls, nums):
return torch.exp(torch.stack(nlls).sum() / sum(nums))
def _load_data(tokenizer):
eval_data = pickle.load(open('calib_data/03-评估数据.pkl', 'rb'))
input_data = []
for data in eval_data:
message = [{'role': 'user', 'content': data['prompt']},
{'role': 'assistant', 'content': data['output']}]
inputs = tokenizer.apply_chat_template(message,
add_generation_prompt=False,
tokenize=True,
return_tensors='pt')
input_data.append(inputs)
return input_data
eval_data = _load_data(tokenizer)
nlls = []
nums = []
with tqdm(range(len(eval_data)), desc="Perplexity -") as progress_bar:
for i in progress_bar:
inputs = eval_data[i].to(estimator.device)
with torch.no_grad():
logits = estimator(inputs).logits
shift_logits = logits[:, :-1, :].contiguous().float()
shift_labels = inputs[:, 1:]
loss_fct = nn.CrossEntropyLoss(reduction='sum')
neg_log_likelihood = loss_fct(
shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1)
)
token_num = shift_labels.shape[1]
nums.append(token_num)
nlls.append(neg_log_likelihood)
curr_ppl = _perplexity(nlls, nums)
progress_bar.set_description(f"Perplexity {curr_ppl:.3f}")
ppl = _perplexity(nlls, nums)
return ppl.item()
 冀公网安备13050302001966号
冀公网安备13050302001966号