



CUDA(Compute Unified Device Architecture)是由NVIDIA推出的一种并行计算平台和编程模型,旨在利用GPU的强大计算能力来加速计算密集型任务。
Doc:https://docs.nvidia.com/cuda/cuda-c-programming-guide/contents.html
1. CUDA 安装
Windows 系统上安装 CUDA 支持的系统版本:
- Microsoft Windows 11 24H2
- Microsoft Windows 11 22H2-SV2
- Microsoft Windows 11 23H2
- Microsoft Windows 10 22H2
- Microsoft Windows 服务器 2022
- Microsoft Windows 服务器 2025
我们先看下自己的 GPU 否持 CUDA,在链接 https://developer.nvidia.com/cuda-gpus 看看有没有自己版本的 NVIDIA 卡型号。如果有,表示支持 CUDA。
首先在 https://developer.nvidia.com/cuda-downloads 下载 CUDA 工具包,按照下图选择:
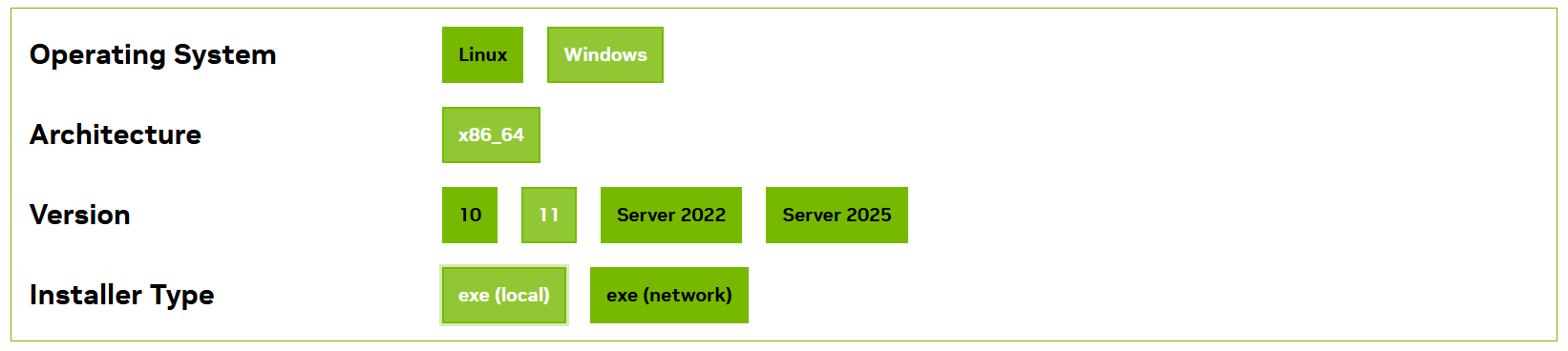
exe(local) 表示完整安装程序,下载之后,双击安装。打开 Visual Studio,选择创建新项目,然后再选择 CUDA 项目模板,如下图:
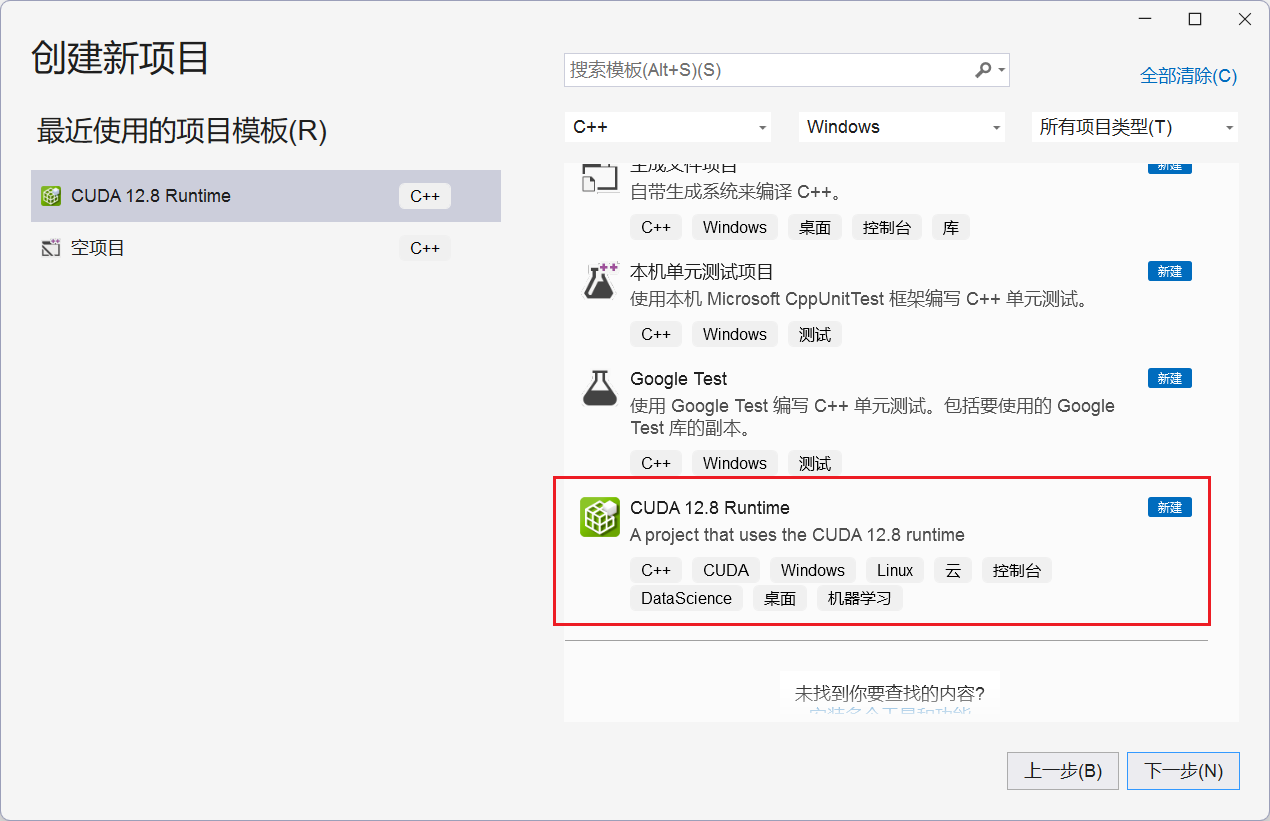
此时,会默认创建名为 kernel.cu 的源码文件,实现了基于 CUDA 的向量加法计算。我们直接编译、运行该程序,如果没有报错,则说明 CUDA 环境安装成功。
2. CUDA 使用
基于 CUDA 进行编程,我们需要了解一些基本的概念:
- 主机(Host):指CPU及其内存。
- 设备(Device):指GPU及其内存。
- 核函数(Kernel):运行在 GPU 上的函数,通过
__global__关键字定义,执行时会被多个线程并行调用。 - 线程层次结构:CUDA采用三级线程层次结构:线程→线程块→ 网格。
- 线程(Thread):执行计算的基本单元。
- 线程块(Block):线程的集合,同一块内的线程可以共享数据和进行同步操作。
- 网格(Grid):由多个线程块组成,网格内的线程块独立执行。
CUDA 程序的开发一般包括以下几个步骤:
- 内存分配:在主机和设备上分配内存,在设备分配内存使用
cudaMalloc函数。 - 数据传输:将数据从主机内存复制到设备内存,使用
cudaMemcpy函数。 - 核函数调用:配置线程块和网格的大小,并通过
<<<...>>>语法启动核函数。 - 结果复制:将计算结果从设备内存复制回主机内存,使用
cudaMemcpy函数。 - 资源清理:释放设备内存,使用
cudaFree函数。
接下来,在 visual studio 中创建 demo.cu 文件,cu 表示该文件的代码包含 cuda 代码。我们接下来,就实现一个简单的向量加法:
#if 1
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>
using namespace std;
#include <cuda_runtime.h>
#include <device_launch_parameters.h>
// 定义仅在 GPU 执行的函数
__device__ int add(int a, int b)
{
return a + b;
}
// 定义在 CPU 调用,GPU 执行的函数
__global__ void vector_add(int* v1, int *v2, int vec_size, int *v3)
{
// 每个线程只负责计算每一组分量的加法和
int idx = threadIdx.x;
if (idx < vec_size)
{
v3[idx] = add(v1[idx], v2[idx]);
}
}
// 定义仅在 CPU 执行的函数
__host__ void print_vector(int* v, int vec_size)
{
for (int i = 0; i < vec_size; ++ i)
{
cout << v[i] << " ";
}
cout << endl;
}
void test()
{
// 1. 在 CPU 创建两个向量
int vec_size = 32;
int* cv1 = new int[vec_size];
int* cv2 = new int[vec_size];
int* cv3 = new int[vec_size];
for (int i = 0; i < vec_size; ++i)
{
cv1[i] = 10 + i;
cv2[i] = 20 + i;
}
print_vector(cv1, vec_size);
print_vector(cv2, vec_size);
// 2. 将数据拷贝到设备上
int* gv1 = nullptr;
int* gv2 = nullptr;
int* gv3 = nullptr;
cudaMalloc(&gv1, sizeof(int) * vec_size);
cudaMalloc(&gv2, sizeof(int) * vec_size);
cudaMalloc(&gv3, sizeof(int) * vec_size);
cudaMemcpy(gv1, cv1, sizeof(int) * vec_size, cudaMemcpyHostToDevice);
cudaMemcpy(gv2, cv2, sizeof(int) * vec_size, cudaMemcpyHostToDevice);
cudaMemcpy(gv3, cv3, sizeof(int) * vec_size, cudaMemcpyHostToDevice);
// 3. 核函数调用
// 分配一个块,每个块中 32 个线程
vector_add<<<1, 32>>>(gv1, gv2, vec_size, gv3);
// 4. 结果复制
cudaMemcpy(cv3, gv3, sizeof(int) * vec_size, cudaMemcpyDeviceToHost);
print_vector(cv3, vec_size);
// 5. 资源清理
cudaFree(gv1);
cudaFree(gv2);
cudaFree(gv3);
delete[] cv1;
delete[] cv2;
delete[] cv3;
}
int main()
{
test();
return EXIT_SUCCESS;
}
#endif
程序执行结果:
10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 30 32 34 36 38 40 42 44 46 48 50 52 54 56 58 60 62 64 66 68 70 72 74 76 78 80 82 84 86 88 90 92
 冀公网安备13050302001966号
冀公网安备13050302001966号