


在 C++ 多线程编程中,线程局部存储(Thread Local Storage)是一项非常重要且值得深入理解的技术。它在提升线程安全性、简化并发设计中发挥着关键作用,是每一位 C++ 开发者都应掌握的核心知识之一。
1. 问题场景
假设在多线程场景下,我们需要创建两个线程来执行 worker 任务,并在 worker 中需要多次调用 log 函数打印日志,我们希望每个线程打印的日志都有独立编号。例如,线程一打印的日志以 [线程一] 为标识,有 log#1、log#2 等编号;线程二打印的日志以 [线程二] 为标识,也有对应的 log#1、log#2 等编号 。
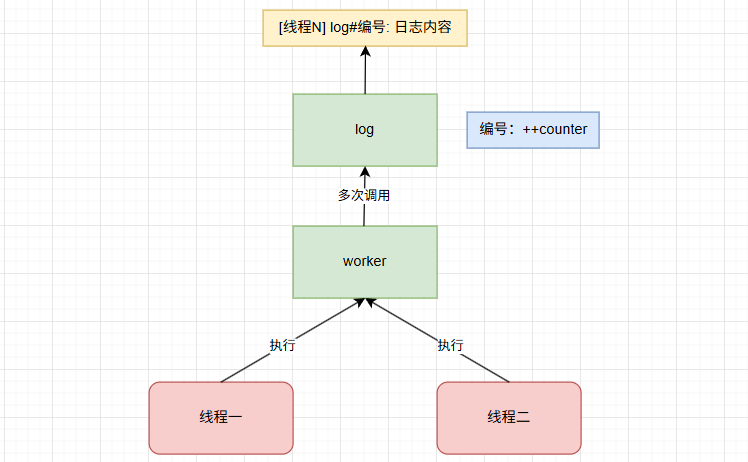
注意:在这个场景中,要求为每个线程分配一个具备线程私有、与线程生命周期同步的变量,专门用于记录该线程的日志编号。
#include <iostream>
#include <thread>
#include <mutex>
// 线程锁,用于同步变量和标准输出
std::mutex lock;
// 普通全局变量
int counter = 0;
// 静态局部变量
//static int counter = 0;
void log(const std::string& thread_name, const std::string& log_message)
{
// 静态局部变量
//static int counter = 0;
// 普通局部变量
int counter = 0;
std::lock_guard<std::mutex> guard(lock);
++counter;
std::cout << "[" << thread_name << "] log#" << counter << ": " << log_message << std::endl;
}
void worker(const std::string& thread_name)
{
log(thread_name, "数据开始处理");
log(thread_name, "数据正在处理");
log(thread_name, "数据处理结束");
}
void test()
{
std::thread t1(worker, "线程一");
std::thread t2(worker, "线程二");
t1.join();
t2.join();
}
int main()
{
test();
return 0;
}
在 C++ 中,对于 counter 变量,我们有四种定义方式:
- 普通局部变量:线程私有,无法做到与线程生命周期同步
- 静态局部变量:线程共享,无法做到与线程生命周期同步(生命周期是整个程序运行期间存在)
- 普通全局变量:线程共享,无法做到与线程生命周期同步(生命周期是整个程序运行期间存在)
- 静态全局变量:线程共享,无法做到与线程生命周期同步(生命周期是整个程序运行期间存在)
最终,我们发现这四种方式都无法满足多线程编程场景下,对 counter 变量的要求。程序输出结果:
[线程一] log#1: 数据开始处理 [线程一] log#2: 数据正在处理 [线程一] log#3: 数据处理结束 [线程二] log#4: 数据开始处理 [线程二] log#5: 数据正在处理 [线程二] log#6: 数据处理结束
为了解决这个问题,我们可以使用 C++11 中引入的 thread_local 关键字,它可以用于定义线程私有、与线程生命周期同步的变量。我们把程序修改如下:
#include <iostream>
#include <thread>
#include <mutex>
// 线程锁,用于同步变量和标准输出
std::mutex lock;
// 线程局部变量
thread_local int counter = 0;
void log(const std::string& thread_name, const std::string& log_message)
{
++counter;
std::lock_guard<std::mutex> guard(lock);
std::cout << thread_name << "地址: " << (long)&counter << std::endl;
std::cout << "[" << thread_name << "] log#" << counter << ": " << log_message << std::endl;
}
void worker(const std::string& thread_name)
{
log(thread_name, "数据开始处理");
log(thread_name, "数据正在处理");
log(thread_name, "数据处理结束");
}
void test()
{
std::thread t1(worker, "线程一");
std::thread t2(worker, "线程二");
t1.join();
t2.join();
}
int main()
{
test();
return 0;
}
程序执行结果:
线程二地址: 2816655625780 [线程二] log#1: 数据开始处理 线程二地址: 2816655625780 [线程二] log#2: 数据正在处理 线程二地址: 2816655625780 [线程二] log#3: 数据处理结束 线程一地址: 2816655644932 [线程一] log#1: 数据开始处理 线程一地址: 2816655644932 [线程一] log#2: 数据正在处理 线程一地址: 2816655644932 [线程一] log#3: 数据处理结束
简单总结一下,在 C++ 中:
- 如果需要定义函数级别的私有变量,使用普通局部变量
- 如果需要定义函数级别的共享变量,使用静态局部变量
- 如果需要定义程序级别的共享变量,可以使用全部变量
- 如果需要定义线程级别的私有变量,可以使用线程局部存储
2. 使用方法
我们先了解下 thread_local 如何定义线程局部变量。首先,它支持定义在全局作用域、类作用域、函数作用域的变量,如下所示:
#include <iostream>
// 全局
// 其他 cpp 文件可以访问
thread_local int a = 10;
// 只能当前 cpp 文件可以访问
static thread_local int b = 20;
// 类内
// 1. 必须定义为静态成员(static thread_local)
// 2. 只能类内声明,类外定义
class Demo {
public:
// 以下定义方式无效
// thread_local int c;
static thread_local int c; // 仅声明,定义需要在外部
};
// 必须在类外部定义:
thread_local int Demo::c = 30;
void test()
{
// 局部
// 下面两种写法等价
thread_local int d = 40;
static thread_local int e = 50;
std::cout << a << std::endl;
std::cout << b << std::endl;
std::cout << Demo::c << std::endl;
std::cout << d << std::endl;
std::cout << e << std::endl;
}
int main()
{
test();
return 0;
}
同时,thread_local 也支持定义不同类型的变量,例如:基本类型、自定义类型、指针类型、引用类型。
#include <iostream>
#include <thread>
// 1. 基本类型
thread_local int number = 100;
void test01()
{
std::cout << number << std::endl;
}
// 2. 类对象
struct Demo { const int value = 100; };
thread_local Demo t_demo;
void test02()
{
std::cout << t_demo.value << std::endl;
}
// 3. 指针类型
thread_local Demo* p_demo = nullptr;
void test03()
{
if (nullptr == p_demo)
{
p_demo = new Demo;
}
std::cout << p_demo->value << std::endl;
if (p_demo != nullptr)
{
delete p_demo;
p_demo = nullptr;
}
}
// 4. 智能指针
thread_local std::unique_ptr<Demo> s_demo;
void test04()
{
if (!s_demo)
{
s_demo = std::make_unique<Demo>();
}
std::cout << s_demo->value << std::endl;
}
// 4. 引用类型(不建议)
Demo demo;
thread_local Demo& r_demo = demo;
void worker()
{
std::cout << std::this_thread::get_id() << " " << &r_demo << std::endl;
}
void test05()
{
std::thread t1(worker);
std::thread t2(worker);
t1.join();
t2.join();
}
int main()
{
test01();
return 0;
}
3. 生命周期
当定义普通全局、静态全局、类静态成员的 thread_local 变量时:
- MSVC 会为每个线程创建一份 thread_local 变量(即使该线程从未使用过这些变量),在线程结束时调用其析构函数
- GCC 会采用延迟初始化策略,只有当某个线程第一次访问
thread_local变量时,才会为其分配并初始化该变量。线程结束时会自动调用析构函数,但仅针对被初始化过的变量。
#include <iostream>
#include <thread>
#include <mutex>
struct Demo
{
Demo() { std::cout << std::this_thread::get_id() << " Demo 构造函数" << std::endl; }
~Demo() { std::cout << std::this_thread::get_id() << " Demo 析构函数" << std::endl; }
void print_demo() { std::cout << std::this_thread::get_id() << " print demo" << std::endl; }
};
#define FLAG 1
#if FLAG == 0
// 类静态成员 thread_local 变量
struct MyClass
{
static thread_local Demo demo;
};
thread_local Demo MyClass::demo;
#elif FLAG == 1
// 全局普通 thread_local 变量
thread_local Demo demo;
#else
// 全局静态 thread_local 变量
static thread_local Demo demo;
#endif
void worker()
{
std::cout << std::this_thread::get_id() << " 开始" << std::endl;
#if FLAG == 0
MyClass::demo.print_demo();
#else
demo.print_demo();
#endif
std::cout << std::this_thread::get_id() << " 结束" << std::endl;
}
void test()
{
std::thread t1(worker);
std::thread t2(worker);
t1.join();
t2.join();
std::cout << "worker 全部结束" << std::endl;
}
int main()
{
std::cout << "主线程ID:" << std::this_thread::get_id() << std::endl;
test();
return 0;
}
在函数内定义的 thread_local 变量,是每个线程私有的,仅在首次执行到该定义位置时构造;线程结束时,如果变量已被构造,则自动调用其析构函数。
注意:只有需要的时候才会被创建。
#include <iostream>
#include <thread>
#include <mutex>
std::mutex lock;
struct Demo
{
Demo() { std::cout << std::this_thread::get_id() << " Demo 构造函数" << std::endl; }
~Demo() { std::cout << std::this_thread::get_id() << " Demo 析构函数" << std::endl; }
void print_demo() { std::cout << std::this_thread::get_id() << " print demo" << std::endl; }
};
void worker1()
{
std::lock_guard<std::mutex> guard(lock);
std::cout << "子线程ID:" << std::this_thread::get_id() << " worker 开始工作" << std::endl;
// 局部线程私有变量
thread_local Demo demo;
std::cout << "子线程ID:" << std::this_thread::get_id() << " worker 结束工作" << std::endl;
}
void worker2()
{
std::lock_guard<std::mutex> guard(lock);
std::cout << "子线程ID:" << std::this_thread::get_id() << " worker 开始工作" << std::endl;
std::cout << "子线程ID:" << std::this_thread::get_id() << " worker 结束工作" << std::endl;
}
void test()
{
std::thread t1(worker1);
std::thread t2(worker2);
t1.join();
t2.join();
std::cout << "worker 全部结束" << std::endl;
}
int main()
{
std::cout << "主线程ID:" << std::this_thread::get_id() << std::endl;
test();
return 0;
}
前面两种定义 thread_local 变量:
- 创建时机,会受到编译器的影响。对于全局和类内方式,MSVC 和 GCC 创建的时机不同。
- 销毁时机,线程结束时才会销毁
有时候我们想手动控制对象的创建和销毁时机,让不同的编译器行为一致,此时可以使用指针类型的线程局部变量。
#include <iostream>
#include <thread>
#include <mutex>
std::mutex lock;
struct Demo
{
Demo() { std::cout << std::this_thread::get_id() << " Demo 构造函数" << std::endl; }
~Demo() { std::cout << std::this_thread::get_id() << " Demo 析构函数" << std::endl; }
void print_demo() { std::cout << std::this_thread::get_id() << " print demo" << std::endl; }
};
thread_local Demo* demo = nullptr;
void do_something()
{
// 在需要的时候创建
if (nullptr == demo)
{
demo = new Demo;
}
demo->print_demo();
}
void worker1()
{
do_something();
do_something();
// 不需要的时候析构
delete demo;
demo = nullptr;
std::cout << "再做一些其他事情" << std::endl;
}
void worker2()
{
std::cout << "随便做点事情" << std::endl;
}
void test()
{
std::thread t1(worker1);
std::thread t2(worker2);
t1.join();
t2.join();
}
int main()
{
test();
return 0;
}
4. 使用注意
在使用线程局部变量时,最需要注意的是在线程池中的使用。我们先简单回顾下线程池的概念,线程池的核心思想是预先创建固定数量的线程,并通过任务队列将需要执行的任务提交给这些线程处理。这样可以避免频繁地创建和销毁线程带来的性能开销,提高资源利用率和系统的响应能力。
线程池的一个重要特点是线程的复用:当一个任务执行完成后,线程不会被销毁,而是被保留用于执行下一个任务。虽然任务之间是相互独立的,但由于它们可能被同一个线程连续执行,因此在某些情况下,线程内部状态的残留可能对后续任务产生影响。
由于线程被复用,thread_local 中保存的变量也会随线程持续存在。如果一个任务在处理过程中设置了某个 thread_local 变量的值,而没有在任务结束时进行清理或重置,那么这个值将在该线程中保留下来。当下一个任务被分配到这个线程时,它访问的将是上一个任务遗留下来的状态,可能会导致逻辑错误或数据污染。
因此,在使用线程池处理任务时,如果涉及 thread_local 变量,应当在每个任务执行结束后主动清除或重置其内容,以避免线程状态泄漏对后续任务产生影响。

 冀公网安备13050302001966号
冀公网安备13050302001966号