
霍夫曼编码(英语:Huffman Coding),又译为哈夫曼编码、赫夫曼编码,是一种用于无损数据压缩的熵编码(权编码)算法。由大卫·霍夫曼在1952年发明。熵用于信息量度量,其本质是信息的平均编码长度,所以也叫熵编码。
霍夫曼编码是依据霍夫曼树。其概念为:给定 N 个权值作为 N 个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。
- 霍夫曼是一棵带权的二叉树;
- 霍夫曼树是带权路径长度最短的树;
- 在霍夫曼树种权值较大的结点离根较近。
怎么理解带权路径最短呢?
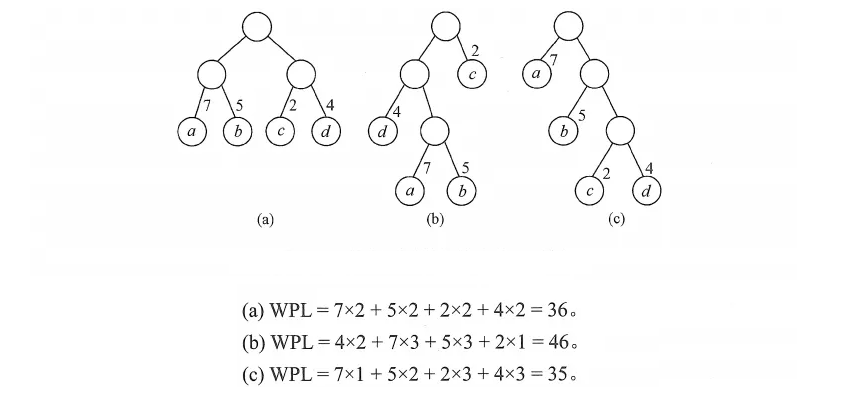
这样一棵树将权值高的结点距离根节点就越近,使得我们能够实现优先访问这些高权重的结点。
1. 构建霍夫曼树
如何将我们自己的数据构建成霍夫曼树呢?步骤如下:
- 先将带权值的结点从小到大排列;
- 将前两个权值最小结点取出当做左右子结点,较小的结点作为左子结点,较大的结点作为右子结点。两个权值的和作为父结点;
- 将新的结点插入到权值结点序列,保持从小到大的顺序;
- 重复 1-3 步骤直到所有的结点都用完啦。
假设:我们有 5、4、2、8 三个结点,首先将其从小到大排列,取权值最小的两个 2、4 构建子树,和作为父结点,较小的值作为左子树,较大的值作为右子树。如下图所示:

接下来将 6 放到原序列中,此时序列变成 5、6、8,取权值最小的两个结点 5、6 构建子树,方法如前面的步骤,如下图所示:

重复前面的步骤,将 11 放到原序列,继续构建子树,如下图所示:
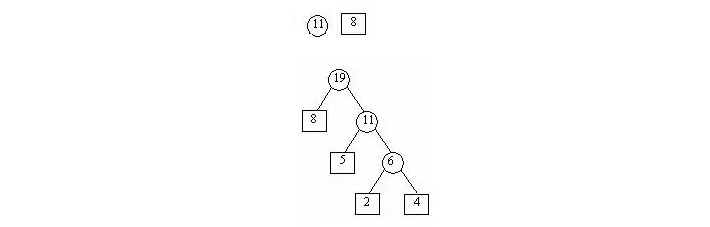
此时,我们就得到一个带权路径长度最短的二叉树,这棵树就叫做霍夫曼树,也叫最优二叉树。我们会发现权值越高的结点就越靠近根节点,也就容易越快的被搜索到。
2. 霍夫曼编码
霍夫曼树出现的一个很重要的目的就是为了实现数据压缩。什么叫做数据压缩?假设:我们有如下内容:
ABCDEFG
当我们想要把这个内容存储到磁盘时,它会占用多大的空间?我们朴素计算下数据的大小(为了提高磁盘读写效率,实际写入磁盘时可能也会占用一个块大小,这里仅仅简单计算下), 1 个字符占用 1 个字节,7 个字符占用 7 个字节。
能不能用少于一个字节的大小来存储该内容呢?
那就需要重新给其编码。原来每个字符占用 8 个二进制位,假设一个字符就占用 4 个二进制位,那么 7 个字符的空间占用就会减少一半。这个把默认 8 位的二进制位重新修改为 4 个二进制位表示,就是重新编码。
注意:重新编码时,可不是机械的删除部分位,保留一部分位就可以了。我们一般都会这么来做:
- 比如一篇文章中,出现频率较高的字符编码较短一些,反之,出现频率较低的可以编码长一些。也就是说,使用不同长度对字符进行编码;
- 长短不等的编码很容易混淆,比如:A 编码为 100、B 编码为 10,这个就容易混淆,因为 B 的编码是 A 编码的前缀,这样在解码的时候就蒙了,倒地是解码 100 还是 10,不同的方式解码出来的字符不同。所以,编码就要求任意字符的编码不能是另外字符的前缀。
上面的要求,基于霍夫曼树就可以实现。我们对文本内容构建霍夫曼树,由霍夫曼树给出每一个字符的编码即可,并且给出的编码都能满足前面提到的 2 条。究竟如何做呢?假设文本内容如下:
ABAABCDCCCE
文本内容共有 11 个字符:
- 统计每个字符出现的频数,作为字符的权值:
- A : 3
- B : 2
- C : 4
- D : 1
- E : 1
- 按照出现的频数对字符进行从小到大排序:D、E、B、A、C
- 接下来,按照前面的过程构造霍夫曼树,如下图所示:
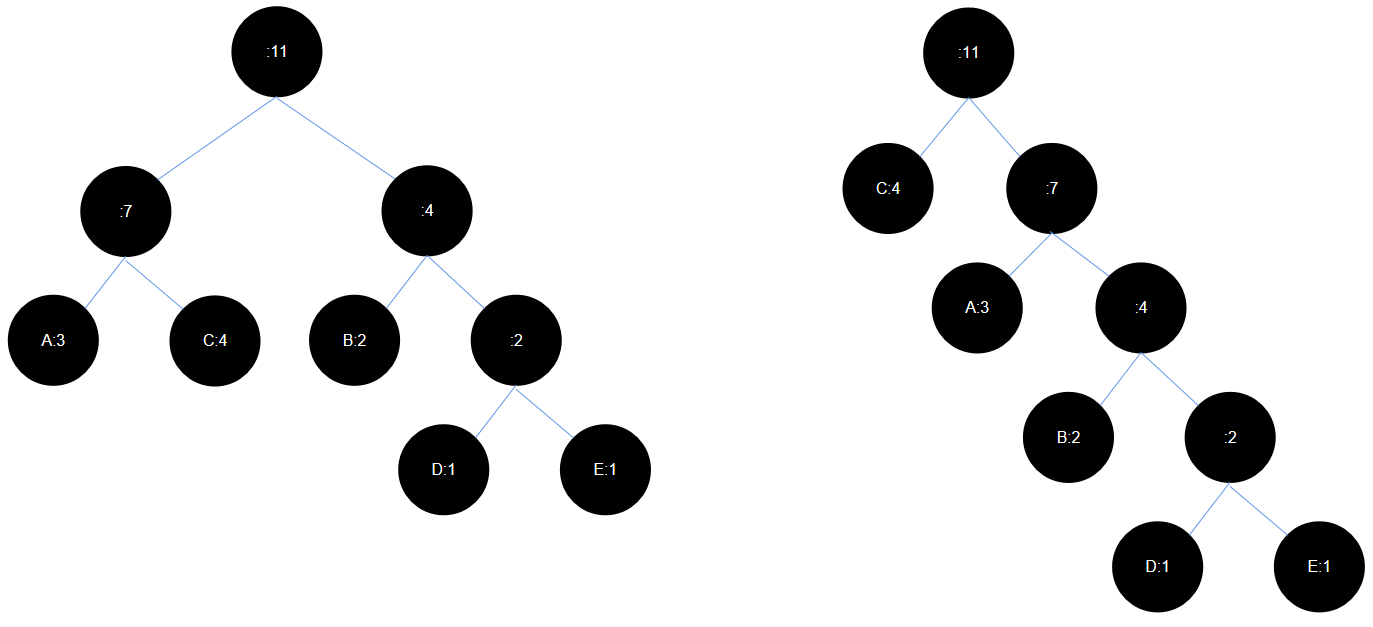
你可能疑惑,怎么出现两个霍夫曼树,是的,霍夫曼构建时并不是唯一的,特别是在构造过程中出现相同的值。那么如何根据霍夫曼树,对不同的字符进行编码呢?
我们把左分支设置为 0,右分支设置为 1,这样就可以实现对字符的编码,假设我们使用第一棵霍夫曼树:
- A 结点:左、左,对应的编码是:00
- B 结点:右、左,对应的编码是:10
- C 结点:左、右,对应的编码是:01
- D 结点:右、右、左,对应的编码是:110
- E 结点:右、右、右,对应的编码是:111
如果我们以此编码对原始的内容进行压缩的话,内容将会变成:
A B A A B C D C C C E 00 10 00 00 10 01 110 01 01 01 111
共 24 个二进制位,原来需要 11 字节存储,现在只需要 3 个字节存储,实现了数据压缩。解码时,将二进制逐个带入霍夫曼树中,例如:
- 逐个遍历二进制位
- 0 表示往左、接下来的 0 表示继续往左,此时达到树的叶子节点:A
- 从根重新开始
- 1 表示往右、0 表示往左,此时达到数的叶子节点:B
- 此时解码出来 AB … 依次类推,直到解码完所有的序列。
大家现在应该明白基于霍夫曼树的编码和解码过程,也就能自己实现一个解压缩工具。虽然在文件压缩时,我们并不会直接应用霍夫曼,但是通过霍夫曼树大家能了解数据解压缩的基本原。其他更高效的解压缩算法只是在基本原理上进行了优化。
回到上面,我们共构建出了两个霍夫曼树,接下来,我们使用第二棵树进行编码:
- A 结点:10
- B 结点:110
- C 结点:0
- D 结点:1110
- E 结点:1111
如果用来重新编码文件内容如下:
A B A A B C D C C C E 10 110 10 10 110 0 1110 0 0 0 1111
共 24 位,3 个 字节,和前面那棵树编码后的内容长度是一样的。
 冀公网安备13050302001966号
冀公网安备13050302001966号